
论文链接
TL;DR: 使用搜索引擎扩充 短文本相关结果,构造正负样本,补充短文本缺失的信息,最终与BERT baseline进行融合获得最终结果,主要是使用了外部信息来进行数据补充与增强。
Abstract
目前的短文本匹配模型通常依赖于匹配的一对短文本,然而短文本通常缺少关键的线索;因此,短文本需要外部知识去弥补更多的语义信息。为了解决这个问题,我们提出了一个新的短文本匹配框架去引入外部知识加强短文本语义表示。我们使用self-attention机制使用外部信息去丰富短文本表示,在英文与中文数据集上,实验表明了我们的框架比SOTA模型好。
1 Introduction
短文本匹配在QA、IR、段落识别等任务中有丰富应用。目前DL模型主要分为基于表示的文本匹配模型与基于交互式的文本匹配模型。后者通常比前者效果好些,但是仍然由于文本较短会缺少重要的语义信息,这种情况在中文语料更为明显,例如下图1。
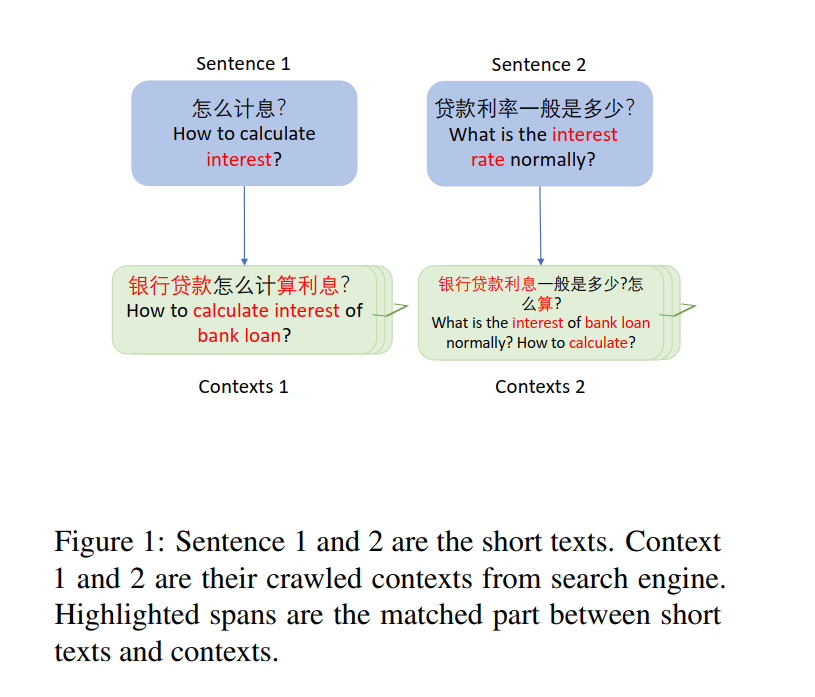
我们通过搜索引擎,将原始句子输入,去查找相关的文本。检索结果通常包含足够的上下文信息,因此匹配模型能使用充足信息完成匹配任务。
从以上观点,我们提出了上下文感知的BERT模型(CBM),通过外部语义相关句子。CBM根据上下文增强注意机制选择所需的上下文并更新短文本表示。
2 Framework
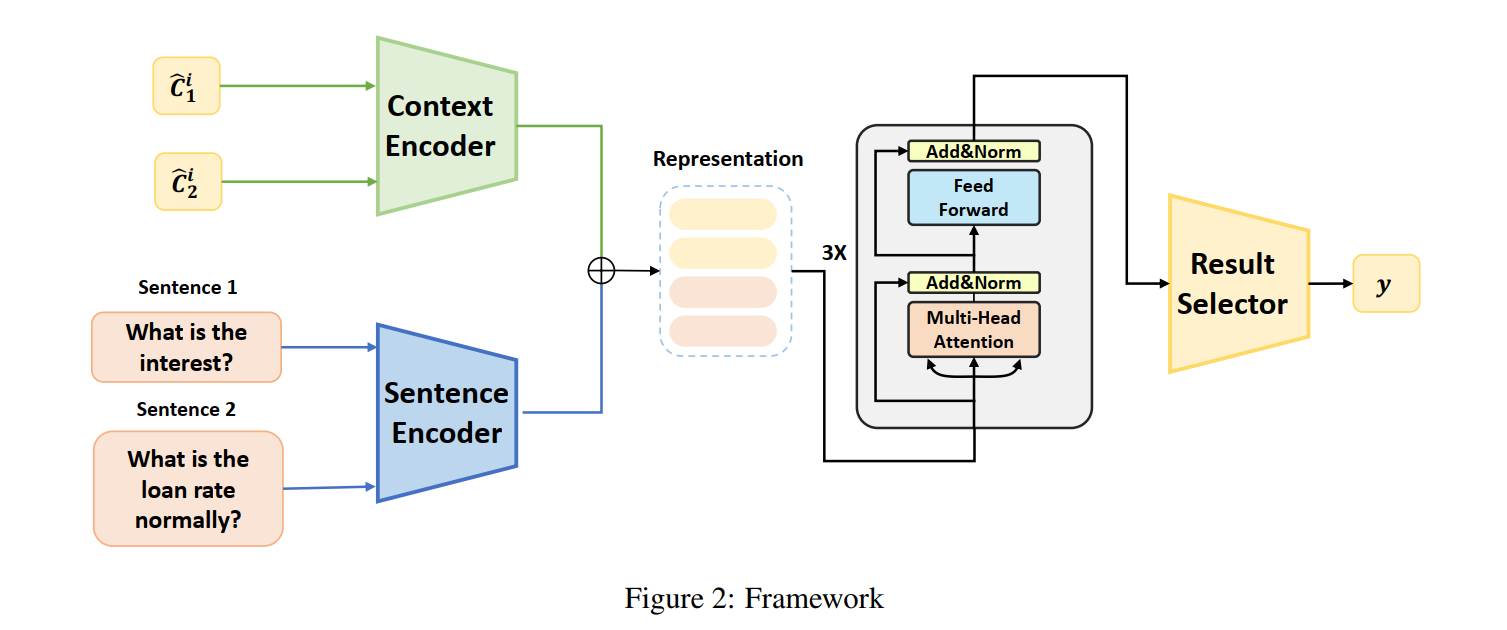
给定两个句子$S_a$、$S_b$,每个句子$S_i$有一个列表$C_i$,它从搜索引擎而来。我们的结构有3个模块,1)文本爬取模块,2)内容选择模块,3)内容加强文本匹配模块。
2.1 Context Crawler
每个句子$S_i$的候选集合表$C_i$是从搜索结果爬取出来的,然而$C_i$是有噪声的。我们首先使用正则等方式进行清洗,同时清洗掉个人信息,最后得到相对干净的候选集$C_i$。
2.2 Context Selector
使用BRET baseline去得到句子$S_i$的候选集合表$C_i$中每个句子的相似度分数,划分正负样本。
2.3 Context-enhanced Text Matcher
使用sentence-BERT去编码句子$S_a$、$S_b$得到$h_a$、$h_b$,同时使用context-BERT编码$C_a$、$C_b$得到$h^c_a$、$h^c_b$,然后将$h_a$、$h_b$、$h^c_a$、$h^c_b$一起拼接输入到一个3层的Transformer,最终获取$h_a$、$h_b$为句子$S_a$、$S_b$的表示。
2.4 Matching Classifier
最终使用$h_a$、$h_b$输入FFN做二分类预测,loss使用BCE。
2.5 Result Selector
由于并不是每一对短文都需要语境增强,因为这些短文对BERT基线有很高的可信度,我们将保留结果和logits。最终概率表达式为
$y_i=\hat{y_i}+\bar{y_i}-1$
$\hat{y_i}$为BERT baseline,$\bar{y_i}$为我们的模型结果,最终结果大于0.5作为label 1,小于0.5为label 0。
3 Experiments
实验结果:
中英文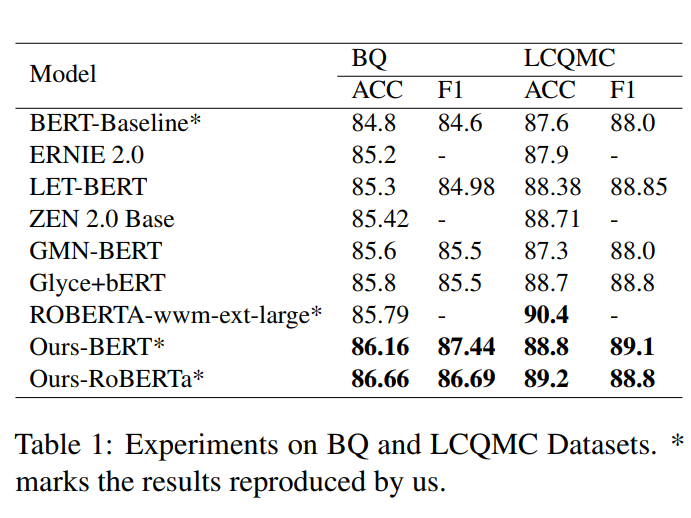
4 Conclusion
本文我们提出的模型用于加强BERT在短文本匹配的能力,以两句话和相关语境为输入,整合外部信息来缓和单词歧义。消融实验表明,语义信息和多粒度信息对文本匹配建模都很重要。