
论文链接
TL;DR:
使用训练词的方式替代了原始BERT训练字的方式,在中英文下表现不错,尤其是NER、MRC等任务,且推理速度和BERT差不多(虽然增加了word embedding参数)
Abstract
标准的BERT分词使用子词分词法,可能将一个单词分为多个子词,如:lossless–>loss、less。这将会带来如下的问题:(1)获得被分成多个子词的单词的上下文向量的最佳方法是什么?(2)如何通过完形填空的方式预测一个单词而不事先知道子词的数量?本篇工作中,我们探索使用词表的方式去预训练BERT相关模型,替代原始的子词预训练方式,称为WordBERT。我们使用不同大小的词表、初始配置、语言训练模型。结果表明:对比基于子词的BERT模型,WordBERT在机器阅读理解和完型填空等任务上有较大的提升。在许多其他自然语言理解任务中,包括词性标注、NER,WordBERT的表现始终优于BERT。模型分析表明,WordBERT比BERT的主要优势在于对低频词和稀有词的理解。此外,我们对WordBERT在汉语上也进行了训练,并在五个NLU上获得了显著的收益。最后,对推理速度的分析表明,WordBERT在自然语言理解任务中的时间开销与BERT相当。
1 Introduction
我们尝试丢弃子词级别的原始BERT模型,使用全词方式的BERT训练方式,探索了不同语言、不同词表大小(500K、1M)、Glove等结构。为了避免更新巨大的词表参数,训练过程中,在每个batch内,我们只更新一小部分词向量参数。虽然WordBERT相比BERT有更多的参数,但在NLU任务中,基本和BERT耗时差不多。
3 Model
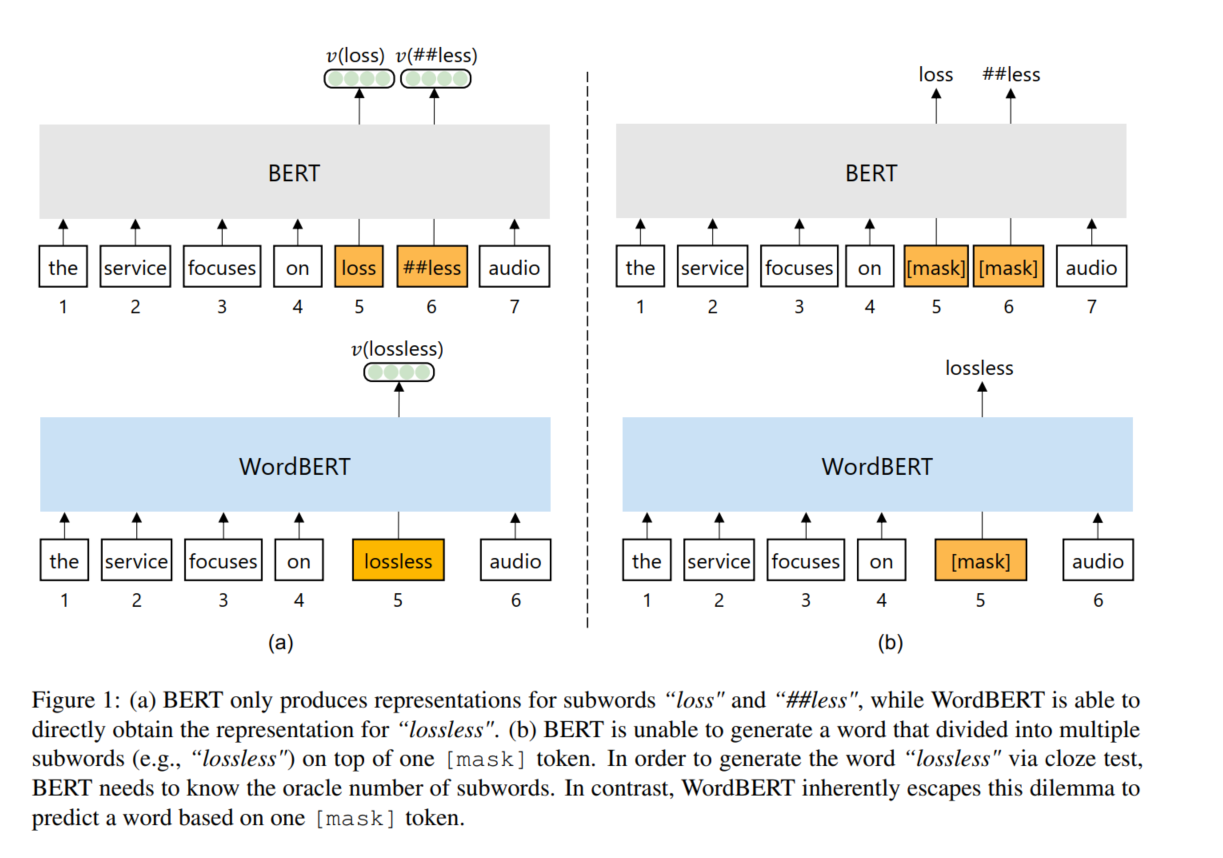
3.1 WordBERT
使用500K、1M大小的词表来训练BERT
3.2 WordBERT-Glove
使用Glove初始化,原始Glove词向量维度为300,使用Glove词表与BERT词表重复的22, 860个词进行训练,将词向量维度从300映射到800,损失函数用MSE。
3.3 WordBERT-ZH
考虑到其他语言,使用WUDAO语料,训练WordBERT-ZH,词表大小278K,维度768,随机初始化。
4 Experiment
我们尝试实验了多种NLU任务,例如完型填空、MRC、词性标注、NER;此外,我们构建了两个数据集去分析模型在不同词频下的性能。同时在CLUE上验证了WordBERT-ZH,最后我们对比了在不同任务上的模型推理速度。
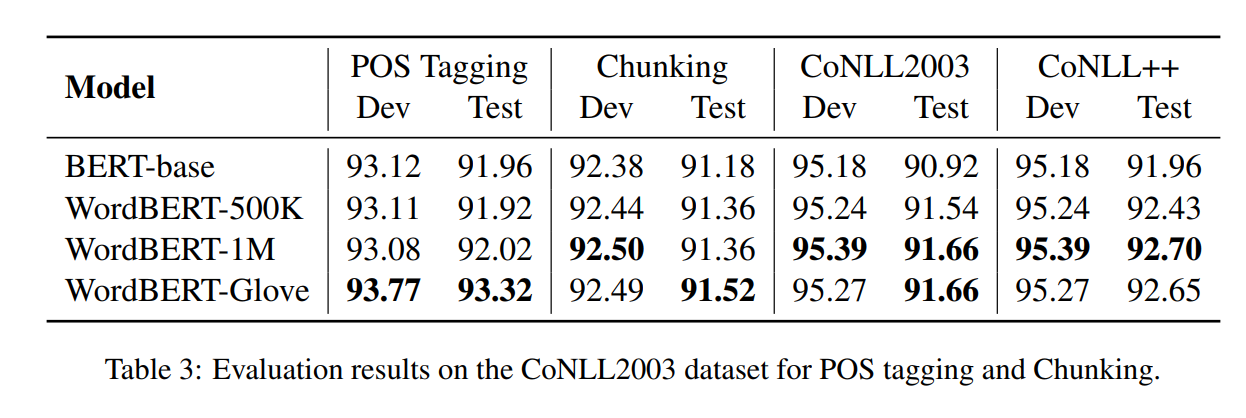
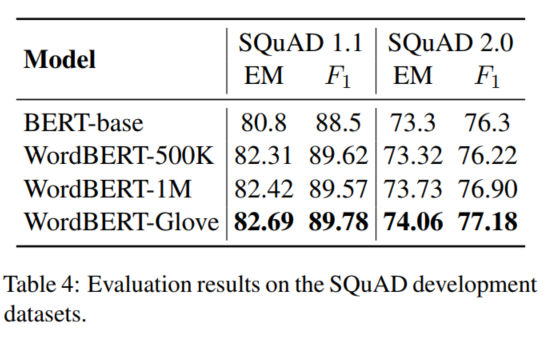
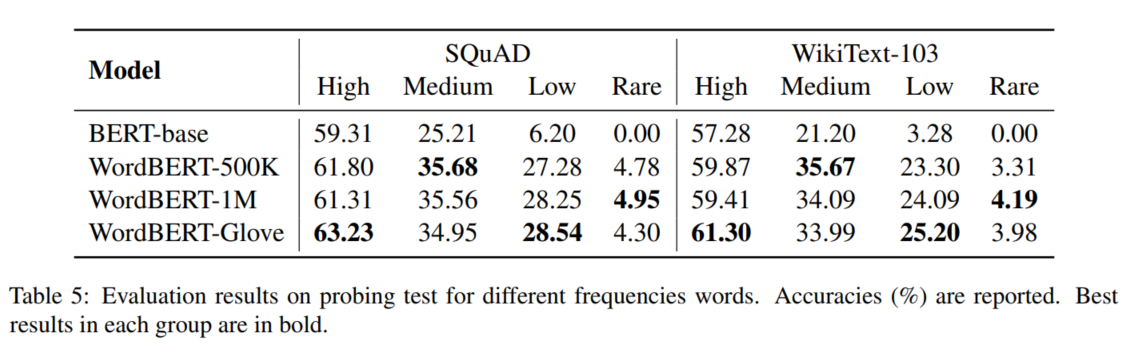
6 Conclusion
在这篇论文中,我们探索了使用基于抽样的训练策略,使用基于单词的预训练方式训练BERT。我们采用不同的配置,即是否使用Glove等预训练词嵌入和不同的词汇量。在MRC、完型填空、词性标注、NER等任务有了较大提升。模型分析表明,我们的模型生成的单词更加多样化和有意义,而BERT倾向于生成一般的单词。在中文领域,WordBERT 于NLU中也有不错的性能。