
论文链接
Abstract
Natural Questions(NQ)数据集给机器阅读理解带来了新的挑战:答案不仅具有不同的粒度(长、短),而且具有更丰富的类型(包括无答案、是/否、单span和多span)。本文针对这一挑战,系统地处理了各种类型的答案。特别是,我们提出了一种新的方法称为Reflection Net,它利用两步训练过程来识别无答案和错误答案的情况。通过大量实验验证了该方法的有效性。在撰写论文时(5月)。2020年12月20日),我们的方法在长答案和短答案排行榜*上均获得前1名,F1得分分别为77.2和64.1。
1 Introduction
Natural Questions(NQ) 数据集的答案提供了两级粒度:长答案和短答案;因此需要模型去在文档和段落级别寻找答案,除了长短答案,还有无答案样本,多span短答案样本,YES/NO答案类型。一些研究人员提出了pipeline方式去抽取短答案,先对长答案进行抽取,然后再抽取短答案。虽然这种方法是合理的,但由于长答案和短答案是分开建模的,因此可能会失去它们之间固有的相关性。还有其他使用联合训练长短答案的方法,以前的方法已经被证明能有效地提高NQ任务的性能,但是很少有工作关注这个QA集合中丰富答案类型的挑战。我们注意到,51%的问题在NQ集中没有答案,因此,模型准确预测何时输出答案是至关重要的。对于其他答案类型,如多span答案或yes/no答案,尽管它们在NQ集合中的百分比很小,但不应忽略它们。相反,在实践中,更倾向于一种能够很好地处理各种答案类型的系统设计。
本文中,我们着重处理无答案类型,我们首先训练所有答案类型的MRC模型,然后,利用训练好的MRC模型对所有训练数据进行推理,训练出第二个模型,称为Reflection model,以预测的答案、上下文和MRC头部特征作为输入,预测出更准确的置信度,从而区分正确答案和错误答案。使用二阶段训练有三个原因:
- 首先,MRC置信度计算的常用方法是基于logits的启发式方法,这种方法不规范,不同问题之间的可比性不强
- 其次,在训练长文档MRC模型时,由于负实例比正实例多,所以对负实例进行了大量的下采样。但在预测时,MRC模型需要对所有实例进行推理。这种训练数据分布差异和预测结果表明,MRC模型可能会被一些负面实例所迷惑,并用高置信度的分数预测错误答案。
- 第三,MRC模型学习了问题的表示、类型和答案之间的关系,而答案不知道预测答案的正确性。
我们的第二阶段模型解决了这三个问题,类似于成为其名称来源的反射过程。通过大量实验验证了该方法的有效性。在撰写论文时(5月)。2020年12月20日),我们的方法在长答案和短答案排行榜*上均获得前1名,F1得分分别为77.2和64.1。
2 Approach
Reflection模型结构如图1所示,由MRC模型和Reflection模型构成,分别用于答案预测和答案置信度预测。

2.1 MRC Model
使用预训练模型作为MRC模型,滑动窗口用于处理长文本文章,然后将问题与文章片断组成一起去构造一个样本,正样本片段中包含答案,负样本片段中不含答案,由于长文本中负样本较多,我们对负样本使用下采样。
MRC模型的输出为span和答案类型,包含$l=(t,s,e,ms)$,t是答案类型,s和e是答案开始结束位置,答案类似是多span时,我们使用BIO去标注多答案(ms),使用Transformer作为Encoder,最终得到$h(x)$
答案类型分类使用[CLS]进行分类,单答案span使用最小化开始和结束的位置进行,多答案类型使用序列标注思想,直接将隐状态通过线性层进行分类BIO,并没使用CRF解码。最终MRC模型的loss:
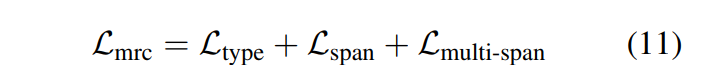
除了预测答案,MRC模型需要输出置信分数,
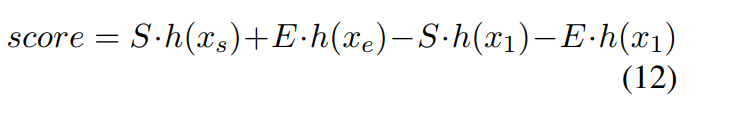
xs,xe,x1是被预测的开始、结束和[CLS]字符
2.2 Reflection Mode
Reflection Mode的目标是一个更精确的置信度得分,区分正确答案和两种错误答案(见第3.4节)。第一种方法是预测一个has-ans问题的错误答案,第二种方法是预测一个no-ans问题的任何答案
Training Data Generation为了生成Reflection Model的训练数据,我们使用训练后的MRC 模型去推理全量数据
- 对于属于每一个问题的所有实例(feature),我们只根据其置信度得分选择预测答案前1名的实例。
- 所选实例、MRC预测答案、其对应的如下头部特征和正确性标签(如果预测答案与真实答案相同,则标签为1;否则为0)一起成为反射模型的训练案例。
Model Training 如图1(a)所示,我们初始化反射模型使用MRC训练好的参数,学习率比MRC模型的学习率小几倍。为了收到重要的MRC模型的状态信息,我们从MRC模型的top层抽取顶层特征当它预测答案时,如表2所示。

顶层特征与[cls]标记的隐藏表示连接,然后是用于最终置信度预测的隐藏层。
反射模型将所选实例x和预测答案作为输入。具体地说,我们创建了一个以答案类型和答案位置标记为元素的字典Ans。我们将应答类型标记添加到[cls]字符中,将位置标记添加到相应的位置字符中,并将空标记添加到其他字符中。
反射模型的隐藏层表示为:
然后和顶层特征拼接[CLS]字符表示$h^r(x_1)$,如下式:
最后获得的置信度分数和二分类损失如下:
式中,如果MRC模型的预测答案(基于x)正确,则y=1,否则为0。对于推理,MRC模型需要为每个问题预测一个文档的所有滑动窗口实例,而反射模型只需要推理一个包含MRC模型预测的最终答案的实例。因此反射模型的计算量很小
3 Experiments
NQ 训练集307,373;验证集7,830;测试集7842 for lb.
3.1 Implementation
先在SQuAD 2.0上ft一遍,再ft NQ
3.2 Baselines
- DocumentQA
- DecAtt + DocReader
- BERTjoint

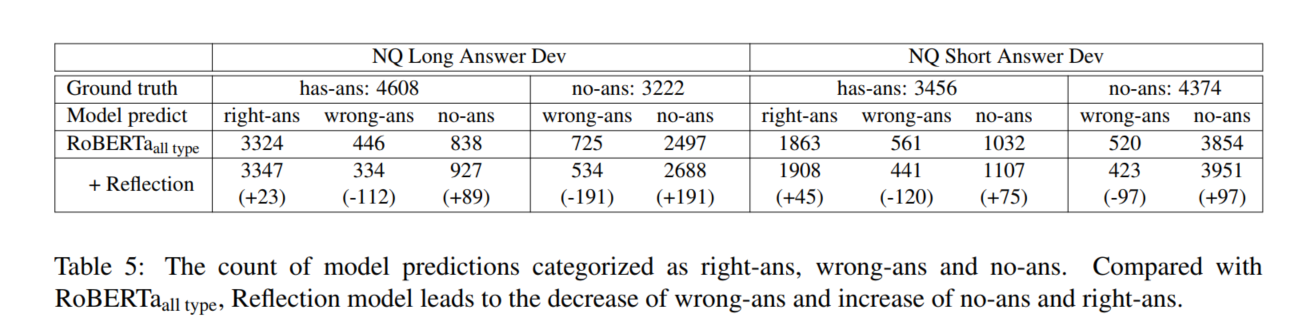
4 Ablation Study
5 Related Work
MRC
Answer Verifier
6 Conclusion
本文提出了一种系统的方法来处理MRC中的丰富答案类型。特别是,我们开发了一个Reflection Model 来处理无答案/错误答案的情况。其关键思想是根据预测答案的内容、上下文和状态,训练第二阶段模型,预测预测答案的置信度。实验表明,该方法在NQ集上达到了最新的结果。由F1和R@P=90在长、短的回答上,我们的方法都超过了之前的SOTA。消融研究也证实了我们的方法的有效性。