
仅用于学习!!!
1.介绍
搜索引擎是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后,将用户检索到的相关信息展示给用户,为用户提供检索服务。搜索引擎包括4个接口,分别是搜索器、索引器、检索器和用户接口。
- 搜索器的功能是在互联网中漫游,负责发现和搜集信息。
- 索引器的功能是理解搜索器所搜索的信息,从中抽取出索引项,输出用于表示文档以及生成文档库的索引表。
- 检索器的功能是根据用户的查询在索引库中快速检出文档,并进行文档与查询的相关度评价,对将要输出的结果进行排序,实现某种用户相关性反馈机制。
- 用户接口的功能是输入用户查询、显示查询结果、提供用户相关性反馈机制。
具体的搜索引擎架构示意图如图2-1所示。
2.搜索引擎的分类
搜索引擎可以分为以下4类:全文搜索引擎、元搜索引擎、垂直搜索引擎和目录搜索引擎。下面对这4类搜索引擎进行具体介绍。
- 全文搜索引擎。计算机通过扫描文章中的每个词,对每个词建立索引,记录词汇在文章中出现的次数和位置信息。当用户进行查询时,计算机按照事先建立好的索引进行查找,并将结果反馈给用户。按照数据结构的不同,全文搜索可以分为结构化数据搜索和非结构化数据搜索。对于结构化数据,全文搜索一般是通过关系型数据库的方式进行存储和搜索,也可以建立索引。对于非结构化数据,全文搜索主要有两种方法:顺序扫描和全文检索。顺序扫描,顾名思义,按照顺序查询特定的关键字,这种方式耗时且低效;全文检索需要提取关键字并建立索引,因此,搜索到的信息过于庞杂,用户需要逐一浏览并甄别所需信息。在用户没有明确检索意图情况下,全文检索方式效率稍显不足。Google和百度都是典型的全文搜索引擎。
- 元搜索引擎。按照功能划分,搜索引擎可以分为元搜索引擎(Meta Search Engine)和独立搜索引擎(Independent Search Engine)。元搜索引擎是一种调用其他独立搜索引擎的搜索引擎,其能对多个独立搜索引擎进行整合、调用并优化结果。独立搜索引擎主要由网络爬虫、索引、链接分析和排序等部分组成;元搜索引擎由请求提交代理、检索接口代理、结果显示代理三部分组成,不需要维护庞大的索引数据库,也不需要爬取网页。元搜索引擎具体实现逻辑如图2-2所示。
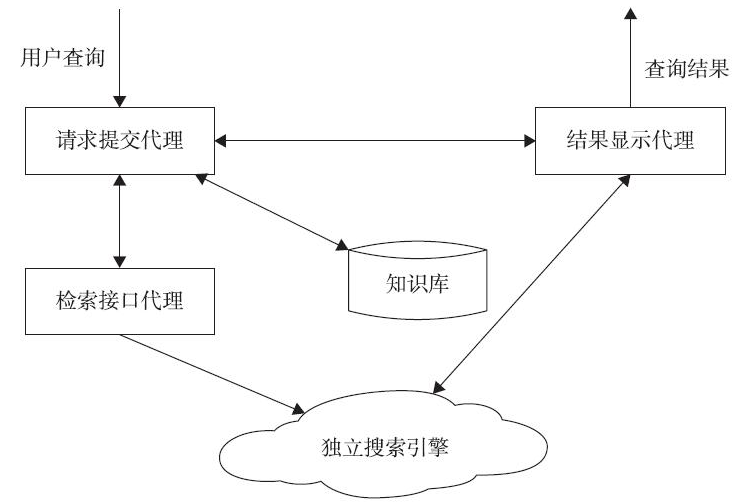
请求提交代理就是将请求分发给独立搜索引擎。元搜索引擎可以按照用户需求和偏好请求实际需要调用的独立搜索引擎,该方式能够有效提升用户查询的准确率和响应效率。检索接口代理是将查询内容转化成独立搜索引擎能够接受的模式,并且保证不会丢失必需的语义信息。结果显示代理是元搜索引擎按照用户的需求采用不同的排序方式对结果进行去重、排序。元搜索引擎常用的排序方式有:相关度排序、时间排序、搜索引擎排序等。
元搜索引擎的整体工作流程如下:用户通过网络访问元搜索引擎并向服务器发出查询,服务器接收到查询内容后,先访问结果数据库,查询近期记录中是否存在相同的查询,如果存在,返回结果;如果没有,将查询进行处理后分发到多个独立搜索引擎,并集中各搜索引擎的查询结果,结合排序方式对结果进行排序,生成最终结果并返给用户,同时保存现有结果到数据库中,以备下次查询使用。保存的查询结果有一定的生存期,超过一定时间的记录就会被删除,以保证查询结果的时效性。 - 垂直搜索引擎。垂直搜索引擎是针对某个行业的专业搜索引擎,是搜索引擎的细分和延伸,对特定人群、特定领域、特殊需求提供服务。它的特点是专业、精确和深入。垂直搜索引擎将搜索范围缩小到极具针对性的具体信息。垂直搜索引擎的结构与通用搜索系统类似,主要由三部分构成:爬虫、索引和搜索。但垂直搜索的表现方式与Google、百度等搜索引擎在定位、内容、用户等方面存在一定的差异,所以它不是简单的行业搜索引擎。用户使用通用搜索引擎时,通常是通过关键字进行搜索,该搜索方式一般是语义上的搜索,返回的结果倾向于文章、新闻等,即相关知识。垂直搜索的关键字搜索是放到一个行业知识的上下文中,返回的结果是消息、条目。对于有购房需求的人来说,他们希望得到的信息是供求信息而不是关于房子的文章和新闻。
- 目录搜索引擎。目录搜索引擎是网站常用的搜索方式,类似于书本章节目录。该搜索方式是对网站信息整合处理并分目录呈现给用户,整合处理的过程一般需要人工维护,更新速度较慢,而且用户需要事先了解网站的基本内容,熟悉主要模块,所以应用场景越来越少。
3.推荐系统协同过滤
目前,基于协同过滤的推荐是推荐系统中应用最广泛、最有效的推荐策略。它于20世纪90年代出现,促进了推荐系统的发展。协同过滤的基本思想是聚类。比如,如果周围很多朋友选择了某种商品,那么自己大概率也会选择该商品;或者用户选择了某种商品,当看到类似商品且其他人对该商品评价很高时,则购买这个商品的概率就会很高。协同过滤又分为三种:基于用户的协同过滤、基于项目的协同过滤和基于模型的协同过滤。
1)基于用户的协同过滤的基本思想是首先找到与目标用户兴趣相似的用户集合,然后找到这个集合中用户喜欢并且没有听说过的物品推荐给目标用户。下图是基于用户的协同过滤的实现逻辑。用户A喜欢商品A和商品C,用户C喜欢商品A、商品C和商品D,用户A和用户C具有相似的兴趣爱好,因此把商品D推荐给用户A。
2)基于项目的协同过滤的基本思想是基于所有用户对推荐对象的评价的推荐策略。如果大部分用户对一些推荐对象的评分较为相似,那么当前用户对这些推荐对象的评价也相似。然后,将相似推荐对象中用户未进行评价的商品推荐给用户。总之,基于项目的协同过滤就是根据用户对推荐对象的评价,发现对象间的相似度,根据用户的历史偏好将类似的商品推荐给该用户。图2-8是基于项目的协同过滤的实现逻辑。用户A喜欢商品A和商品C,用户B喜欢商品A、商品B和商品C,用户C喜欢商品A,通过这些用户的喜好可以判定商品A和商品C相似,喜欢商品A的用户同时也喜欢商品C,因此给喜欢商品A的用户C也推荐了商品C。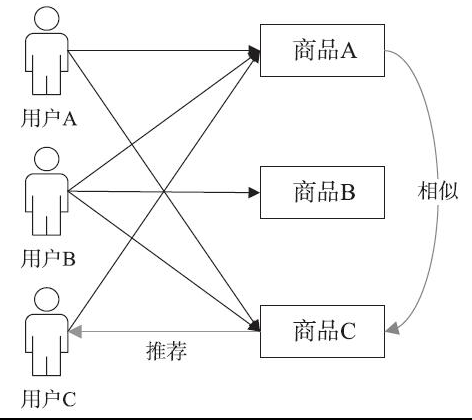
3)基于模型的协同过滤的基本思想是基于样本用户的喜好信息训练一个推荐模型,然后根据实时的用户喜好信息进行推荐。其和上述两种协同推荐的不同点在于先对已有数据应用统计和机器学习的方法得到模型,再进行预测。常用的方法有机器学习方法、统计模型、贝叶斯模型和线性回归模型等。
基于协同过滤推荐的优点有:1)可以使用在复杂的非结构化对象上;2)能够发现用户新的兴趣爱好,给用户带来惊喜;3)以用户为中心的自动推荐,随着用户数量的增加,用户体验也会越来越好。缺点在于:1)存在冷启动问题,即在没有大量用户数据的情况下,用户可能不满意获得的推荐结果;2)存在稀疏性问题,即用户大量增长的同时,评价差异性会越来越大,推荐对象也越来越多,导致大量的推荐对象没有经过用户评价,部分用户无法获得推荐结果,部分推荐对象无法被推荐。