
本文为biendata视频笔记,仅用来学习,侵删。
Background
风格转换:在不改变原来句子语义情况下,将原句子x和目标风格sj输入,生成含有目标风格sj的句子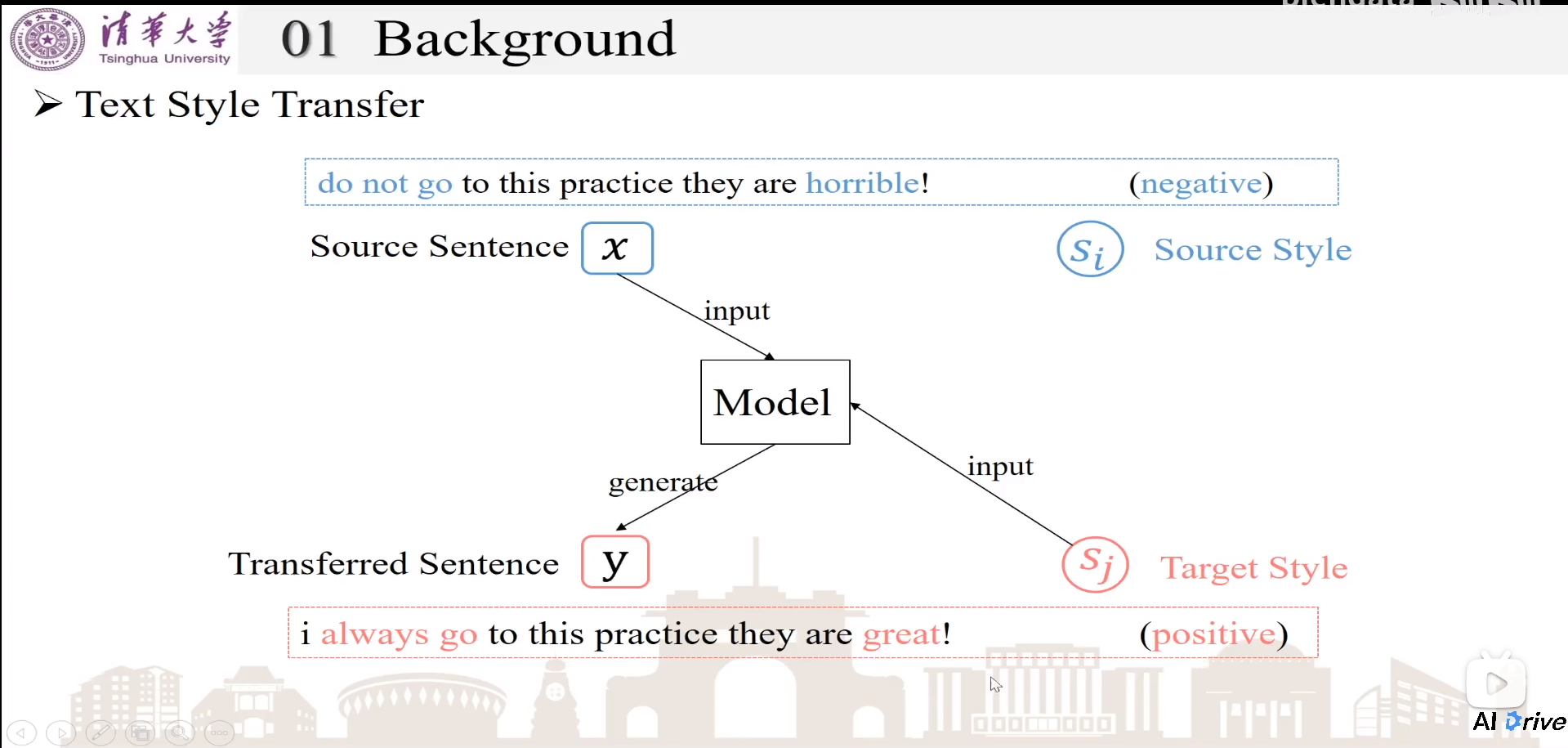
Applications
- 文本润色,将非正式句子转为正式句子
- 评论、对话的自动生成
- 风格特征写作

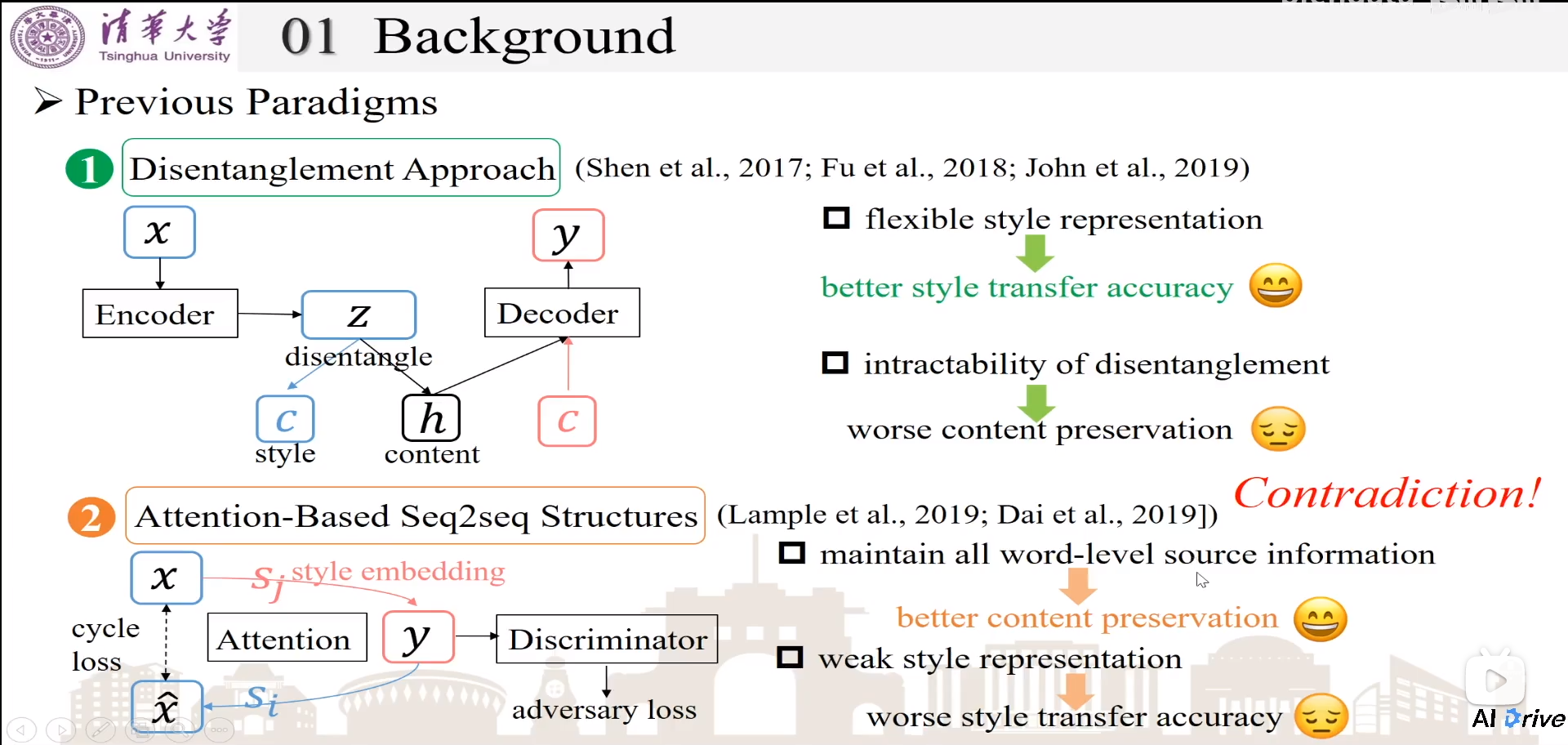
Previous Paradigms
风格转换,需要表示句子内容和target style。
- 解耦方式(Distentage)。将encoder之后的隐状态,拆出风格表示特征c和文本表示特征h,将h和target style同时输入到decoder中,生成y。这种方式的缺点:内容保留不太好;优点:风格表示容易控制、灵活的。
- 基于Attention的Seq2Seq。使用Seq2Seq结构,使用attention将x和y去对齐,并且在生成y时候,使用目标风格style embedding去监督生成对应风格的句子。cycle loss:先用目标风格sj监督x生成y,然后再用先前风格si将y再生成回去x’,x’和x计算相似loss。可以保证迁移之后的句子仍然保留原来的语义。同时使用判别器去判别迁移后的y是否真的有目标风格,促进风格迁移生成!优点:保留词级别的信息,几乎没有语义丢失。缺点:风格的信号比较差,风格迁移效果不太好。
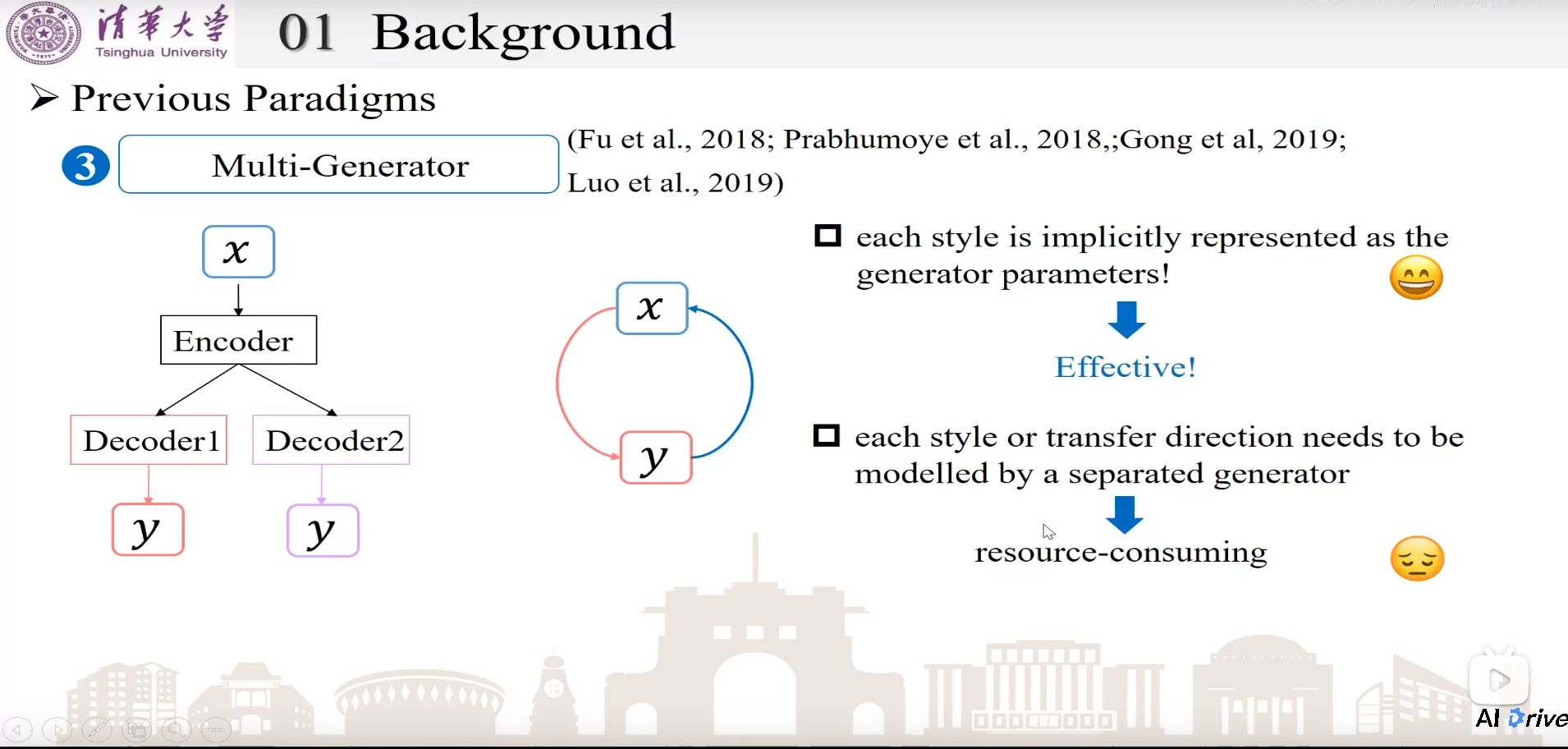
- Multi-Generator。通过不同generator来实现不同风格上的style生成。相当于每个decoder就代表了各自的风格。为了保留内容,在使用另一个decoder重新构造生成x’。优点:效果很好!缺点:资源需求比较多,需要多个seq2seq。
- Locate and Replace。找出句子中和风格相关的词,进行替换,保留和风格无关的词。优点:较为精确,能够实现较好的风格转换和内容保留。缺点:需要一个风格词表;对于超出词义的风格迁移,效果不好,上升到更深的语义级别效果不好!

Motivation
结合Attention-based Seq2Seq和潜在风格空间Latent Style Space,去构建更好的风格迁移和内容保留。
Methodology
之前的VAE方法,假设每个句子是独立的,每个句子都去单独输出隐状态风格z,不能充分考虑全局信息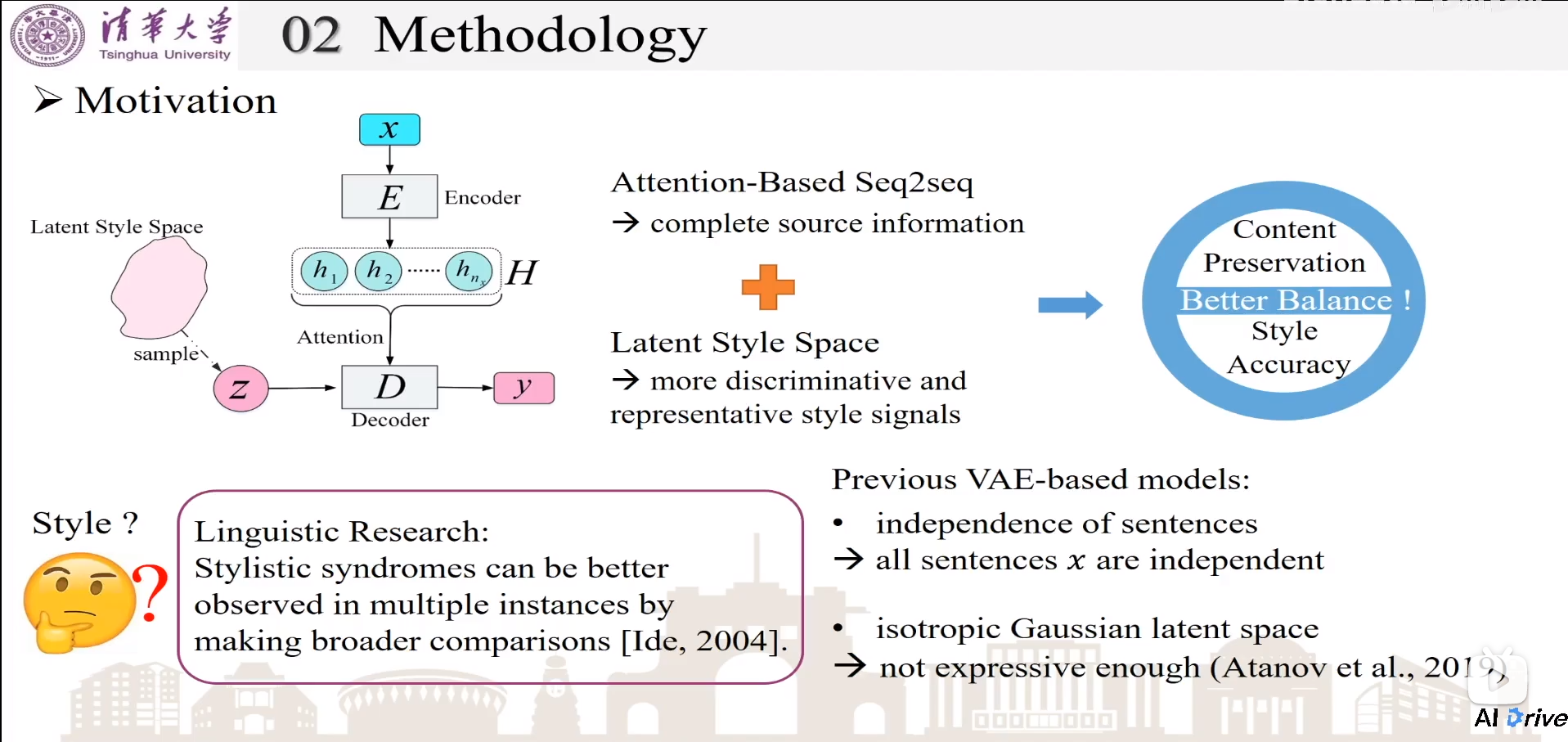
K为K个句子都包含同样的风格j。
一个原句子encoder编码原句子x为H,一个风格encoder(将K个句子都包含同样的风格j的句子集)进行风格编码为z,一个decoder对H和z进行解码。
style encoder使用生成式流模型,假设初始为高斯分布z0,经过多次复杂变换之后,生成更为复杂的分布zt,能更充分表示风格。
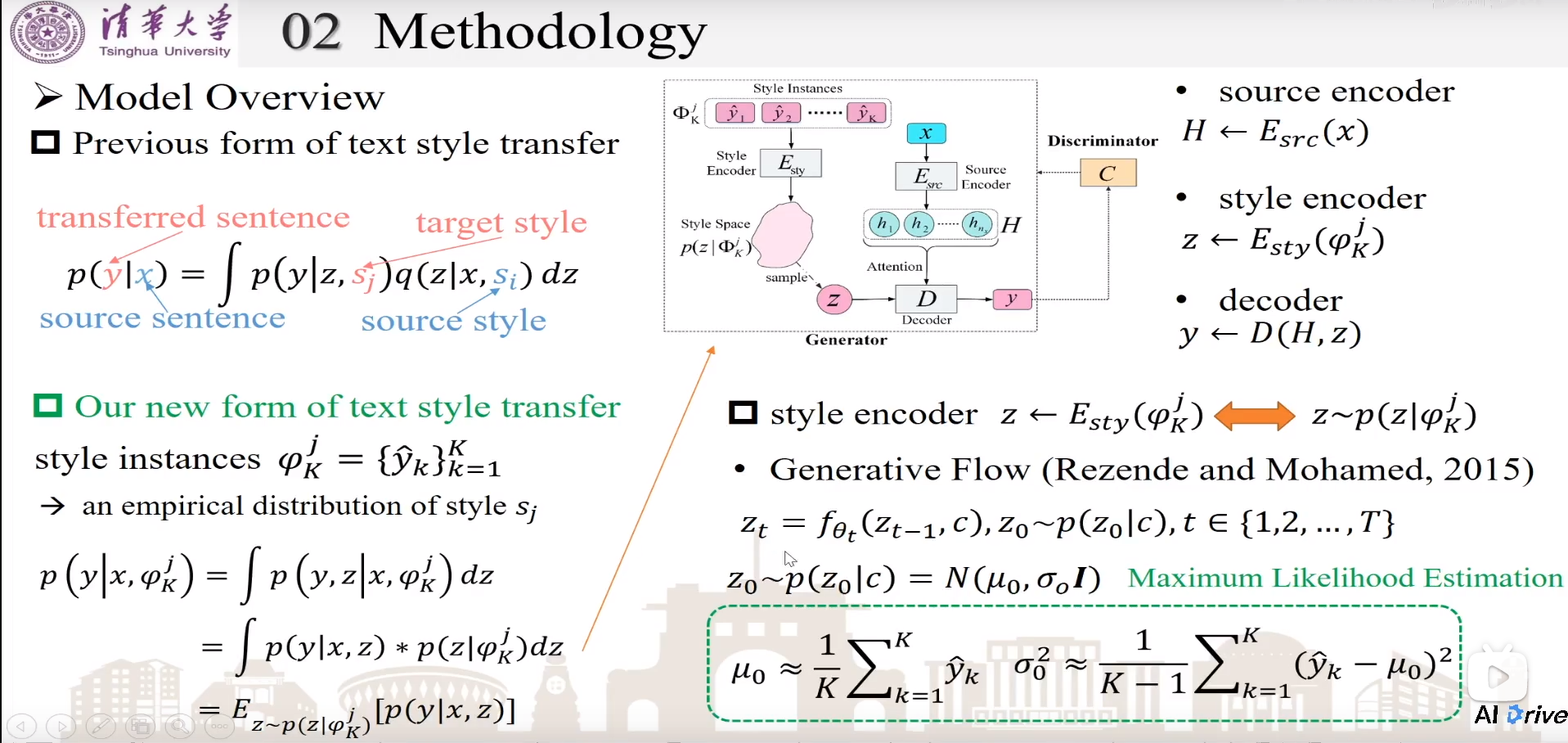
Training
Unsupervised Training
- Cycle Consistency Loss:先将x转为y再转回去x’,计算x’和x的交叉熵。
- Reconstruction Loss:给定原句x和原句风格s,希望能重新生成原句x
- Adversarial Style Loss:提供style相关的判别对抗loss
Semi-Supervised Training

Experiment
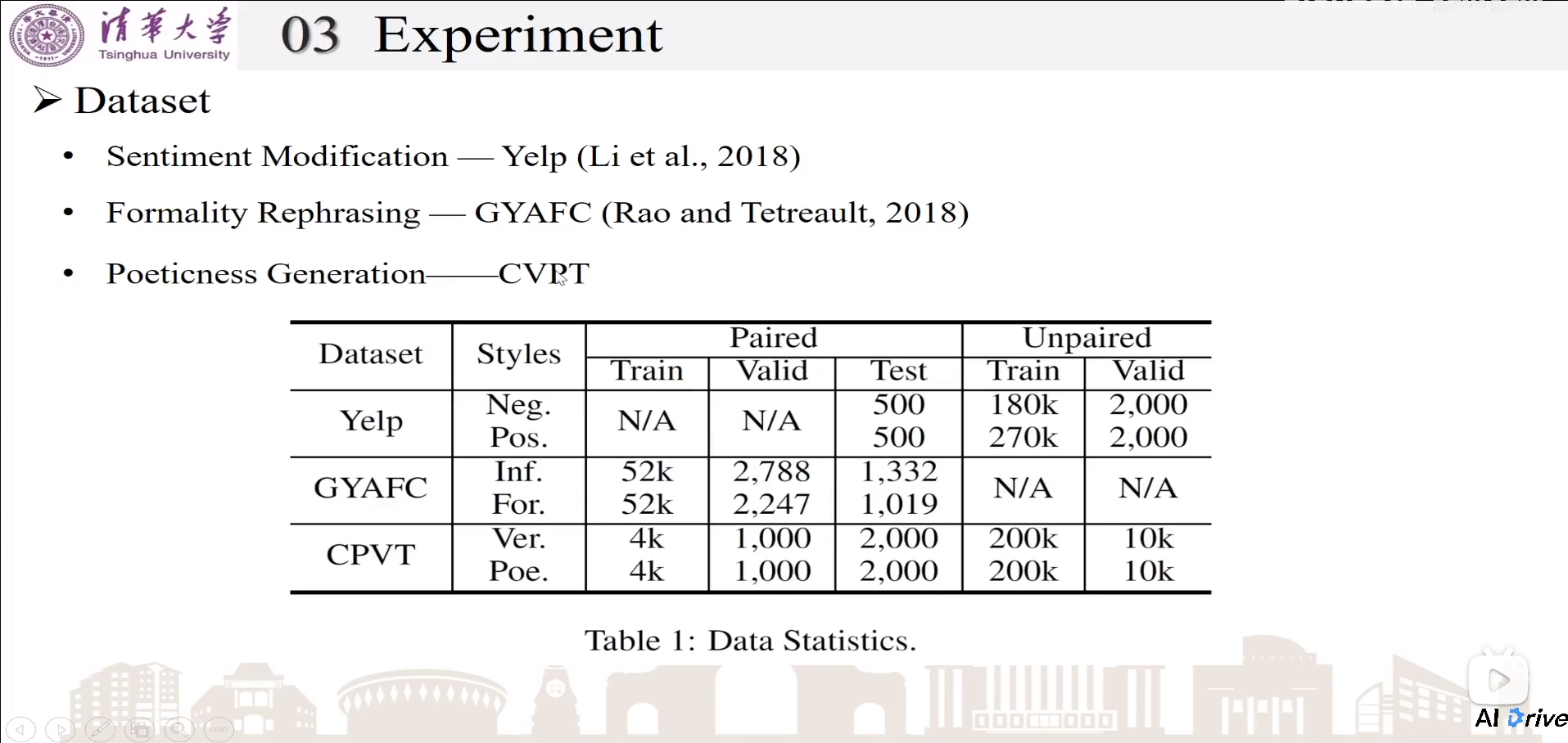
Dataset
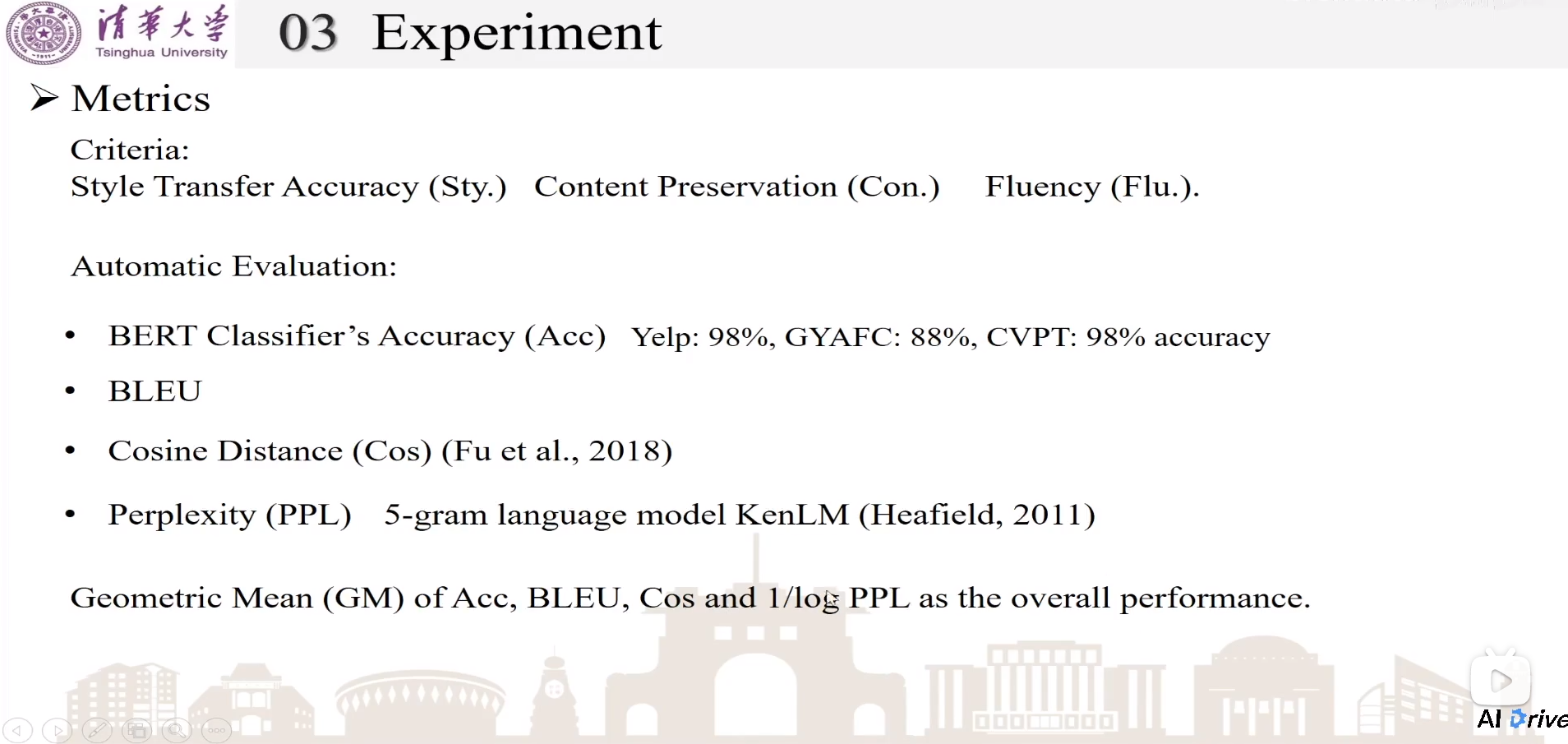
Metrics
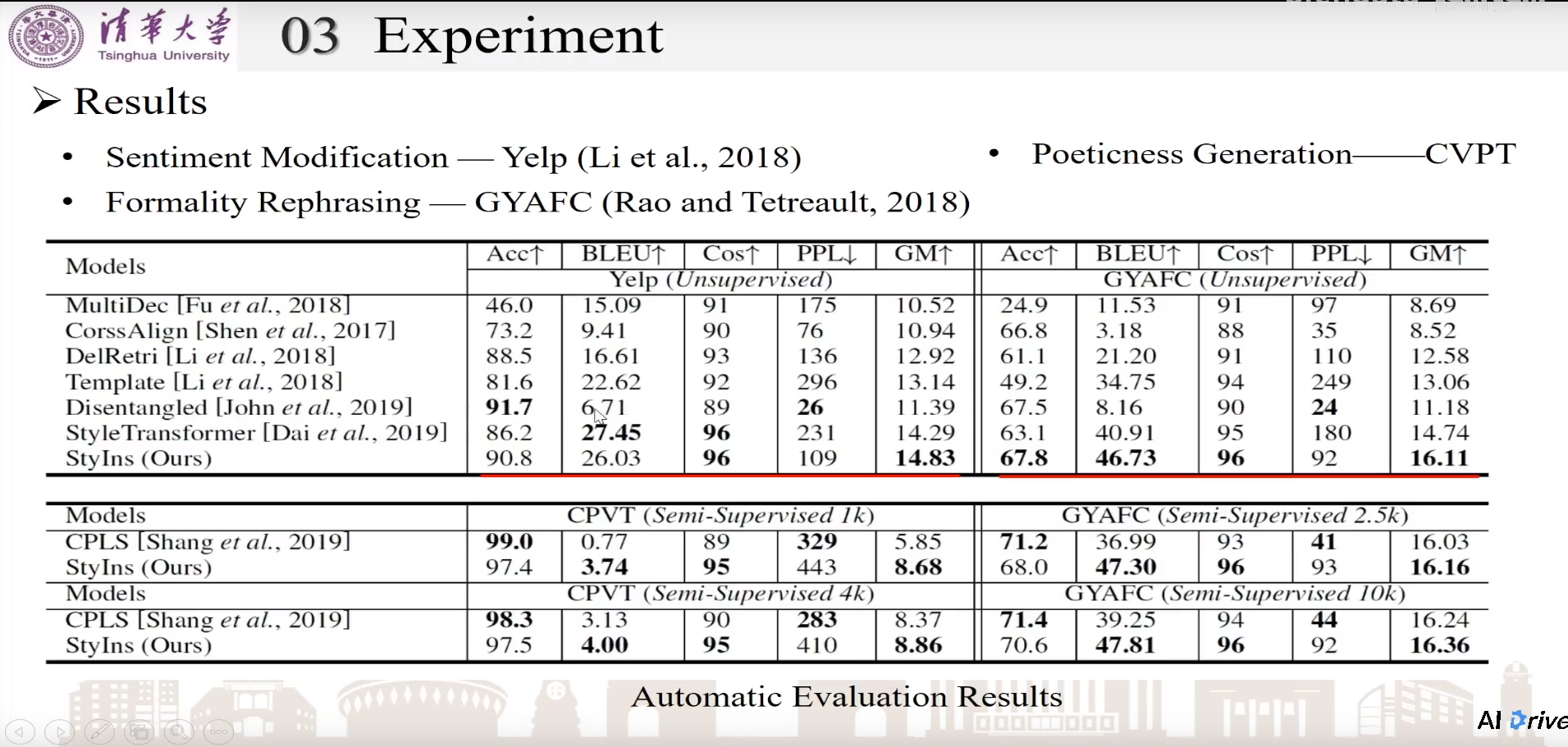
Results
人工评测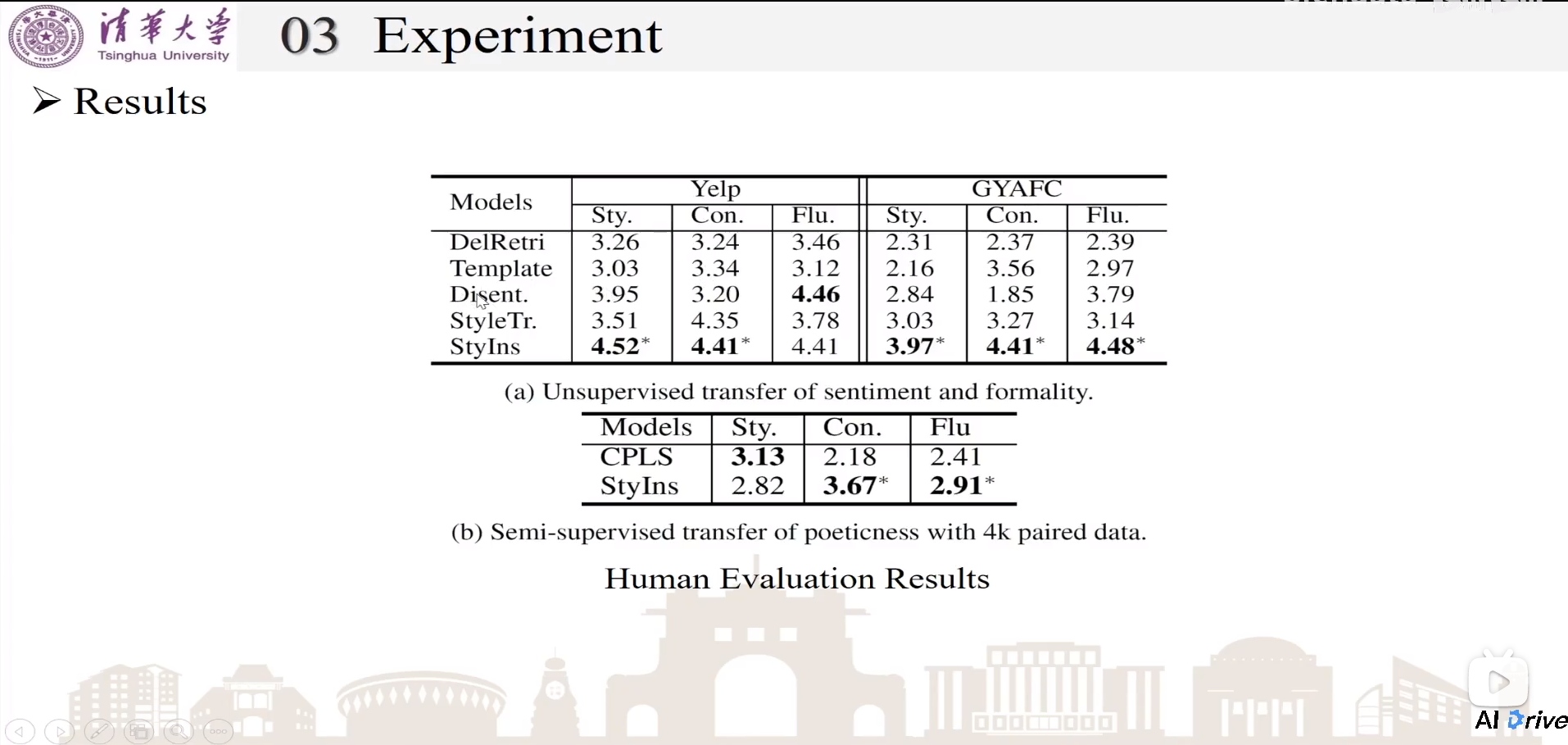
Cases

Conclusion
