
论文链接
Abstract
基于Transformer的LM展现了显著的自然语言生成能力。由于其巨大的潜力,控制这些LMs的生成文本正受到关注。虽然已经有了不少研究去控制被生成文本的高级属性(情感、主题等),但仍然缺少对内容上词级别、短语级别的准确控制。本文中,我们提出了Content-Conditioner(CoCon)在细粒度级别,去使用目标内容控制一个语言模型的输出。在我们的自我监督的方法中,CoCon学习帮助LM完成一个部分观察到的文本序列,通过调节LM中保留的内容输入。通过实验,我们证明了CoCon可以自然地将目标内容合并到生成的文本中,并以Zero-shot的方式控制高级文本属性。
1 Introduction
基于Transformer的LM在海量语料上进行训练,然后去预测下一个token通过对数似然损失(log-likehood)。控制LM的输出逐渐吸引了人们的注意。像从零开始训练一个修改过的LM来合并目标文本属性[这样的方法成本很高,而对特定属性的预训练LM进行微调则限制了文本控制的范围。PPLM没有修改LM的架构,通过属性来控制被生成的文本。尽管在控制诸如主题和情感之类的高级文本属性方面是有效的,但是相同的目标属性可能会生成在单词和短语级别具有显著不同的内容文本样本,从而为对LM生成的文本的内容进行更细粒度的控制留下一个gap。为了举例说明情绪控制的例子,一篇以“彼得”这样的名字的提示文本开头的文章后面可以是描述彼得性格的文本,关于他在某个特定时间正在做什么,甚至是关于“彼得广场”这样的非人类实体,以积极的方式。对LMs输出内容的更精细控制可以为生成符合事实或没有不适当内容的文本铺平道路。
我们提出的Content-Conditioner (CoCon),以缩小这一差距,通过指导预训练的LMs的文本输出同时包含目标内容。基本上,CoCon包括三个部分:1)编码器,2)解码器和3)CoCon块。CoCon采用预训练LM作为编码器和解码器,通过CoCon块将目标内容合并到编码文本表示中,然后将内容条件表示传递给解码器进行生成。为了训练CoCon块,我们提出了一种自监督学习方法,其中训练数据由预训练LM本身生成的文本样本组成。通过将每个文本序列分成两段([xa;xb]),CoCon学会了通过将xb本身作为内容输入来帮助LM重建丢失的后段(xb)。
我们提出了CoCon的损失函数和content masking,在产生高质量文本的同时,对来自不同来源的内容进行限制。由于CoCon块的大小是LM的一小部分,并且没有对LM的权重进行微调,因此训练成本明显低于从头开始训练LM。对比于strong baselines,CoCon也可以进行高等级的文本属性控制(例如主题和情感),通过zero-shot的方式。此外,CoCon在同化多个目标内容方面具有通用性,其内容调节的强度可以在推理过程中通过内容偏差项进行灵活的调整。本文中,我们使用GPT-2作为LM。我们主要贡献如下:
- 我们提出CoCon的基于条件的内容语言生成方法。
- 我们引入了一种自我监督学习方法,在这种方法中,CoCon在给定未来token的信息时学习完成文本序列。
- 通过消融试验和与PPLM和CTRL等强基线的比较,我们研究了CoCon如何有效地影响文本生成的内容,以及如何有竞争性地控制主题和情感等高级文本属性。
- 我们展示了CoCon在整合多种内容方面的多功能性,文本生成中内容调节的灵活性,以及它与其他控制方法(如PPLM)的互补性。
2 Related Work
之前的属性控制的文本生成方法大多基于RL和GAN进行训练。与CoCon不同,这些方法中对预定属性的要求限制了生成文本的可能类型。
CTRL是最近的一种方法,它通过使用控制代码生成受控的流畅文本,这些控制代码是在生成过程中预先添加到文本中的元数据。虽然它使用GPT-2结构生成高质量的文本,但是它的控制代码在训练过程中也是预先确定的。
最接近我们的工作是PPLM,它试图通过相对较小的“可插拔”属性模型来控制已经预训练的LM上的文本。尽管PPLM的灵活设计也支持受控生成,而无需像CoCon中那样对LM进行再培训或微调,但我们的方法旨在将生成控制在更局部的内容级别,而不是高级的文本属性。另一个核心区别在于训练,CoCon的自监督学习免除了对标记数据的需要,例如用于训练PPLM的属性鉴别器模型的数据。PPLM中的加权解码试图通过在解码步骤中提高目标词的概率来控制输出文本,但已被证明产生不连贯文本。
文本风格转换是通过将文本从一种风格转换到另一种风格来控制文本属性的相关领域。一些这样的研究使用自动编码器来分离文本的风格和非风格的潜在表征。这种分离使得文本在保留大部分内容的同时,能够在潜在空间改变样式。另一项工作是识别与文本语料库中特定风格相关的n个属性标记,并通过替换它们来编辑文本的风格。从本质上说,风格转换改变现有的文本,而不是生成文本,需要预定义的属性。
3 Content Conditioner (CoCon)
Motivation
在基于语言模型的文本生成任务中,通常使用自回归的方式进行生成: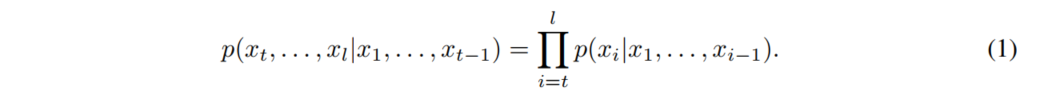
之前的控制文本生成任务中,p(x)可以通过目标属性或者控制代码进行控制文本的情感或者主题:
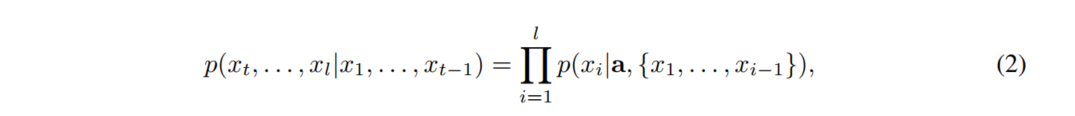
虽然这些方法生成是流畅的,并且可以很好地与目标属性对齐,但是输出文本${x_t,...,x_l}$是在全局属性(例如情绪/主题)级别上控制的,而不是在更局部的内容(例如单词/短语)级别上控制的。由于存在大量可能的${x_t,...,x_l}$候选项,这些候选项将与先验文本和目标属性很好地对齐,因此在随机字符采样过程中,生成的文本样本包含非常不同的内容。这激发了一种对输入目标内容c进行条件处理的方法,以便对文本生成进行更细粒度的控制:
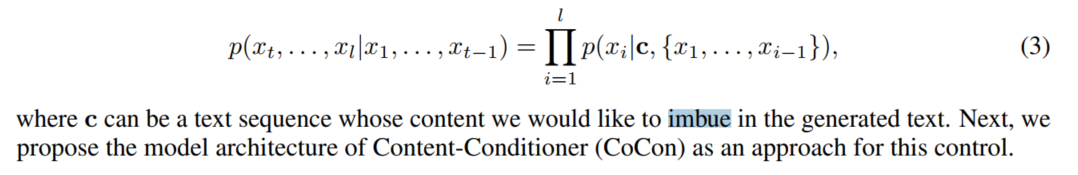
Model Architecture
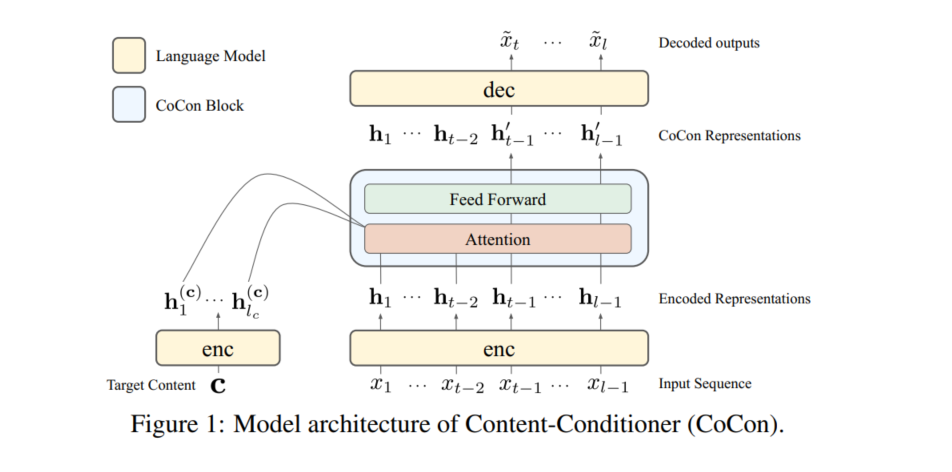
我们提出的CoCon(图1)通过在我们的实验中加入一个基于预训练Transformer的语言模型(LM)GPT-2,在保持流畅性的同时控制生成文本的内容。
LM的生成可以分为两个独立的部分:编码器(enc)和解码器(dec)。编码器充当一个特征提取器,接收输入序列的嵌入并在断点处输出其中间表示,即$h_{:t−1}=enc(x_{:t−1})$。随后,解码器接收该表示并输出下一字符的logit,即$o_t=dec(h_{:t−1})$,从而产生
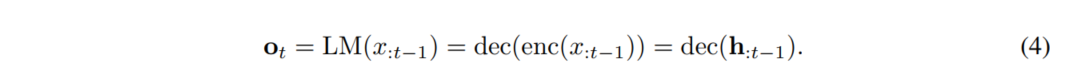
从等式4中,我们可以看到表示(h)是控制下一个字符logits(o)的表示。实际上,我们通过CoCon块用目标内容输入(c)对h进行条件化,从而转换h
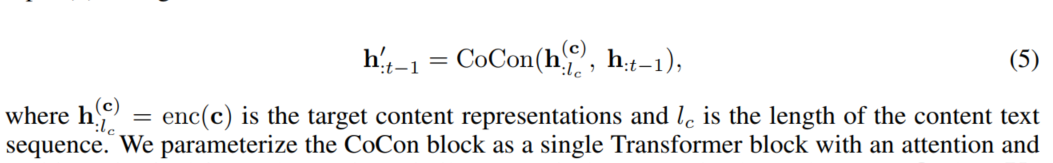
我们参数化CoCon模块将其作为一个单层的Transformer模块,其中包含一个attention层和 FFN层。与典型的LM attention层类似,Query(Q)、Key(K)、Value(V)矩阵通过表示$h_{:t−1}$上的线性变换来计算,其中$Q,K,V\in R^{(t-1)xd}$,d是表示的维数。为了关注内容表示$h_{l_c}^{(c)}$,还计算内容键和值$K^{(c)},V^{(c)}\in R^{l_cxd}$,并在计算CoCon注意输出之前concat到原始注意矩阵: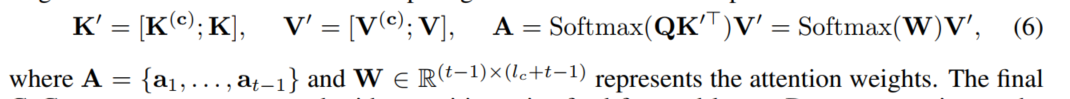
最后的CoCon输出通过位置前馈层进行计算。通过连接到t−1之前的表示并将其传递给解码器(dec),下一个logit以及随后的字符$\hat x_t$现在由c进行调节:
Multiple Content Inputs对于多个目标内容的输入,处理方法较为简单,将多个目标内容的K和V进行拼接再计算即可。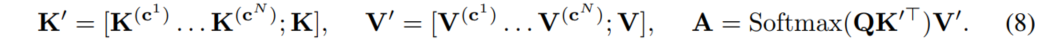
Strength of Content Conditioning
在CoCon的注意机制中,我们可以通过偏置W(等式6)中与内容输入(c)相对应的注意权重来改变内容对输出文本的调节程度。更具体地说,可以通过注意对内容值$(V^{(c)})$的softmax加权来改变c对输出文本的影响。在生成期间,可以选择向内容注意权重$W_{:,:l_c}\in R^{(t-1)xl_c}$添加正偏项(τ内容),以增加V(c)的影响,促进内容调节,而负偏项可以相反地降低内容调节效果。我们讨论了变化τ含量的例子在4.4节中。
3.1 Self-Supervised Learning
我们可将一个序列$x=\{x_1,...,x_{t-1},x_t,...,x_l\}$分为两部分:$x^a=\{x_1,...,x_{t-1}\}$和$x^b=\{x_t,...,x_{l}\}$,即$x=[x^a;x^b]$。在现实世界中,$x^b$的替代品可能有很多,可以流利地从$x^a$开始。再加上文本采样的随机性,这意味着,如果没有关于$x^b$的信息,仅用LM从$x^a$重建完整x的概率可能很低。
Self Reconstruction Loss
自重构损失$L_{self}$就是让控制文本$c=x^b$,之后要生成的就是$x^b$自己,这一步是让模型能够学习结合控制文本的内容。
Null Content Loss
无内容损失$L_{null}$,即令$c=null$,这时候CoCon就退化为一个简单的语言模型,为了能够生成流畅的文本。
Cycle Reconstruction Loss
循环重构损失$L_{cycle}$通过两个不同文本互为控制文本来生成质量更高的文本。假设现在有两个不同的文本:$x=[p;q]$和$x'=[p';q']$,进行如下操作:
- 首先将p’作为引导文本,将q作为控制文本,生成新文本
$q^1=f(p',q)$。显然,q1的目的是在和p’保持语言流畅,且尽可能包含q的内容。 - 再将p作为引导文本,将q1作为控制文本,生成新文本
$q^2=f(p,q^1)$,这是让q2和p保持流畅,同时尽可能包含q1的内容。 - 既然q2包含q1的内容,并且q1包含q的内容,要么就是q2包含q的内容,且要和p保持流程,此时就是q本身。
因此,循环重构损失就是以q为真值去优化q2,反过来也可以以q’为真值去优化q’2
Adversarial Loss
最后用到常用的对抗损失$L_{adv}$,让生成的文本更接近真实的文本。
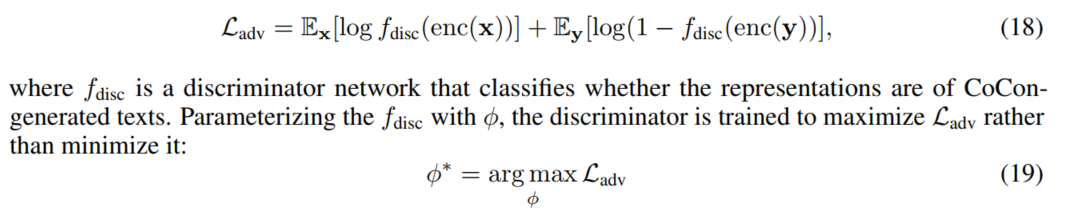
Full Training
组合以上四个loss即为最终需要优化的目标:
4 Experiments
本文在三个可控文本生成任务上进行实验,情感可控生成,主题可控生成,文本可控生成。
文本可控生成
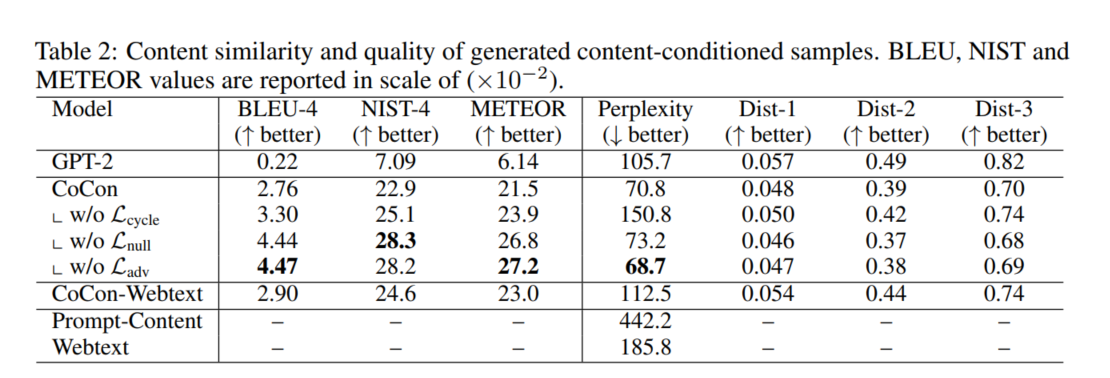
文本引导的文本生成评估指标有BLEU、NIST、METEOR、PPL和Dist-1/2/3。由于没有现成的该任务的数据集,故本文随机从预训练的GPT-2中采样3000个样本,均匀分为三组,每组的控制文本c的长度为5,10,20个BPE长度,所生成的句子x长度都是100。把它们作为测试集。训练集则是随机从GPT-2所产生的句子中获取。此外,CoCon还在大小为250K的Webtext.上训练,以探究不同训练数据来源的影响。结果如下表所示。可以看到,CoCon在结合控制文本c.上比GPT2好太多。在这个实验。上,不加一些损失会有更低的PPL以及更高的BLEU、NIST、METEOR等值,比如去掉$L_{null}$或者$L_{adv}$模型的BLEU值会更高,这是因为这两个损失相比之下更关注生成文本的流畅度而不是与控制文本c相结合。
主题可控文本生成
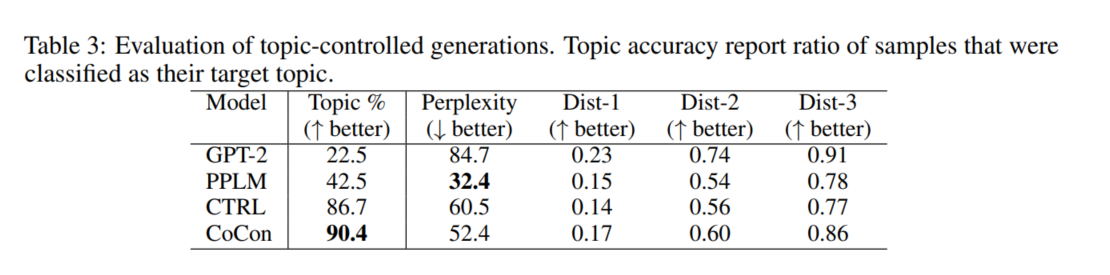
在主题可控任务上,比较的基线模型有PPLM和CTRL,都是当前很强的模型。为验证主题相关性,训练一个分类器用于评估主题程度。下表是实验结果:
情感可控文本生成
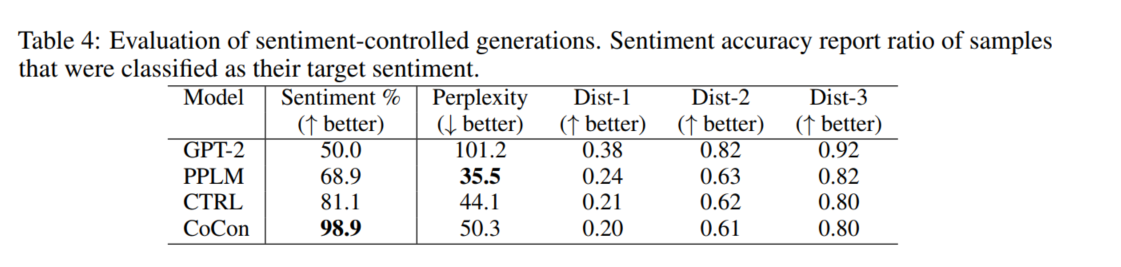
情感可控生成任务采用二分类情感,下表是实验结果,和主题任务类似,CoCon在情感相关度上显著优于其他模型,这说明CoCon能够更加紧密地控制文本c。
实例分析
下图是不同的$t_{content}$生成的不同文本,显然,值越大就越和控制文本相关,但是越容易生成不相关的内容。

多个控制文本输入的结果实例:
5 Conclusion
我们提出了CoCon为了细粒度的控制基于神经网络的生成文本。CoCon可以被有效训练通过一个自监督的方式,并且它与已经生成高质量文本的预训练语言模型兼容。通过我们的实验,CoCon被证明能够顺利地将目标内容合并到生成的文本中,并控制高级文本属性。这种新的控制方式为更真实、更安全的文本生成带来了希望,促进了神经文本生成在实际应用中的应用。