
论文链接
Abstract
在大型文本语料库上训练的大型基于transformer的语言模型(LMs)已经显示出无与伦比的生成能力。然而,如果不修改模型结构或对特定属性数据进行微调,并且需要大量的再训练成本,那么控制生成语言的属性(例如,切换主题或情感)是困难的。我们提出了一个简单的可替代方案:可控制语言生成的即插即用语言模型(PPLM)。它将预训练的语言模型与一个或多个简单的属性分类器相结合,这些属性分类器无需对语言模型进行任何进一步的训练就可以指导文本生成。在我们提出的规范场景中,属性模型是简单的分类器,由用户指定的bag of words或单个学习层组成,其参数比LM少100000倍。采样需要前向和后向传递,其中来自属性模型的梯度推动LM的隐藏激活,从而指导生成。模型样本展示了对一系列主题和情感风格的控制,广泛的自动化和人工注释评估显示属性对齐和流畅性。PPLMs的灵活性在于,可以使用不同属性模型的任何组合来指导文本生成,这将允许本文给出的示例之外的多种创造性应用。
1 INTRODUCTION
基于Transformer的PLMs在大量无标注的语料中训练,然后使用对数似然损失函数进行训练。然而,一旦这样的模型被训练,在不修改模型结构以允许额外的输入属性或对属性特定的数据进行微调的情况下,控制生成文本的属性就变得很困难。
可控的文本生成需要对$p(x|a)$进行建模,a是想要的可控属性,x是需要被生成的文本。然而,生成模型只需要去学习$p(x)$。在计算机视觉领域,Nguyen et al.(2017)的即插即用生成网络(PPGN)开发了一种生成具有不同属性的图像的机制,方法是将判别器(属性模型)$p(a|x)$与基本生成模型$p(x)$插在一起,并从结果的$p(x|a)\propto p(a|x)p(x)$中采样,有效地创建条件生成模型从任何提供的属性模型动态建模。以类似的方式,我们提出了用于条件语言生成的即插即用语言模型(PPLM),它将一个或多个简单的属性模型p(a|x)组合在一起,可以是一个Bag-of-Words(BoW)或单层分类器的形式,也可以是一个预训练的无条件语言模型p(x)。我们从得到的组合模型中取样,在潜在的表示空间中遵循梯度,这种方式受到了(MALA)的启发。
优化是事后在激活空间中执行的,因此不需要重新训练或微调。文本控制是细粒度的,强度参数决定属性影响多大的强度;强度为0则完全恢复原始模型p(x)。这种设计允许极大的灵活性:用户可以将最先进的生成模型与任意数量的属性控制器结合起来,生成模型可能很大,而且很难训练。属性模型可能更易于训练或未经训练,并且在推理过程中可以灵活地组合多个控制器。在本文中,我们演示了使用GPT-2 345M参数模型作为通用语言模型p(x)的PPLM方法,但是该方法适用于任何基于transformer的文本生成器的任何表示空间,并且允许与任何属性模型p(a|x)组合。
我们演示了使用多个属性控制器的受控生成,这些控制器在生成过程中组装和组合,每个控制器具有不同的强度,充当一组“控制旋钮”,将生成的文本调整为所需的属性(参见表1中的示例),我们关键的贡献如下:
- 我们提出了用于控制语言生成的即插即用语言模型,讨论了它与现有工作的关系,以及如何从PPLM中进行采样。
- 我们证明了对一系列属性的文本生成控制,包括7个主题,每个主题使用一个BoW定义,以及1个简单的情感判别器。我们使用自动评估(分别训练的困惑和情绪模型)和人类评估(属性相关性和流畅性)来量化有效性。所有的评估都指向PPLMs生成属性控制的流畅文本的能力
- 我们对比了CTRL和GPT-2,我们的方法,没有任何LM训练,在属性相关性和流利性方面都是标杆,并且经常优于基线
- 我们表明,PPLM方法可以用来文本消除毒性,遵循负梯度模型训练,生成有毒内容是可能的,同时也可以用其检测毒性。我们还展示了PPLM如何用于结构受限的故事写作

2 RELATED WORK
Controlled generation当前的控制文本生成方法大多涉及到使用RL方法ft预训练模型,训练GAN或者训练条件生成模型。与我们方法不同之处,这些方法并不是即插即用,因为整个模型需要针对每个特定属性分别进行微调。我们的方法不需要对任何条件生成模型进行再训练,语言模型和条件模型都可以灵活组合。
Noisy Channel Modeling不少人使用香农噪声信道理论为了提升Seq2Seq建模,他们的方法翻译源语言句子y到一个目标语言句子x通过首先对前向模型的采样$p_{forward}(x|y)$,然后基于概率$p_{backward}(x|y) \propto p(x)p(y|x)$重排样本。PPLM对样本进行打分使用相同的基本公式,但由于我们没有前向模型$p_{forward}(x|a)$,我们依赖于潜在空间的更新。作为一个基线,我们使用$p(x)$作为前向模型,然后重排序。我们将看到,在某些场景中工作得相当好,而在其他场景中工作得很差
Weighted decoding有的研究者使用判别器或者BoW去控制语言生成,为了考虑用于解码的评分函数,对解码过程进行了修改。See等人(2019)注意到,使用加权解码(WD)进行控制是困难的,通常会导致牺牲流畅性和连贯性。此外,Ghazvininejad et al.(2017)强烈依赖于从特定主题的一组关键字中取样,并且不允许以不必包括一组关键字的方式偏向于主题的生成。类似的,Baheti等人提出了一种解码策略用于在对话系统中生成感兴趣的回复,使用BoW和词向量,随机采样方法可以被使用去受限于模型的生成到确定的关键词和主题。我们使用带权重的解码作为基线。
Text Style Transfer在语言建模之外,语篇风格迁移是一个相关的研究课题。有的研究者训练VAE for 风格迁移依赖于学习区分风格和内容的潜在表示。Li et al.证明了一种基于条件生成模型的简单方法的有效性,该方法将与属性相关的n-gram替换为与所需属性对应的n-gram。我们的方法与上面方法一个关键的不同之处在于,我们使用了一个线下的判别器,基于此鉴别器执行优化。
最近,Lample等人(2019年)采用了一种从无监督语言翻译到风格转换的方法,在这种方法中,去噪自动编码器的训练目标包括重建损失和回译损失的加权组合。虽然上述方法在风格转换任务上取得了令人印象深刻的成功,但主要的焦点是不受控制的语言生成,而且这些方法也不是即插即用的。
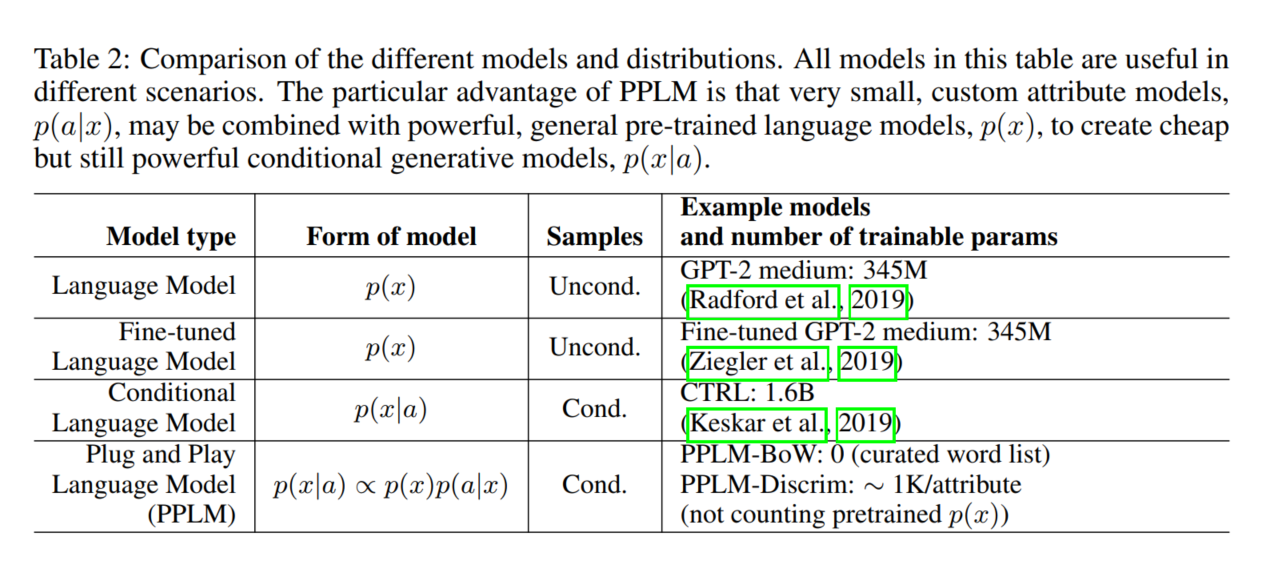
3 PLUG AND PLAY LANGUAGE MODELS
3.1 LANGUAGE MODELING WITH TRANSFORMERS
给定一个句子$X={x_0,...,x_n}$,语言模型被训练去计算序列$p(X)$的无条件概率。这个概率可以应用递归链式法则进行表示为乘积形式:
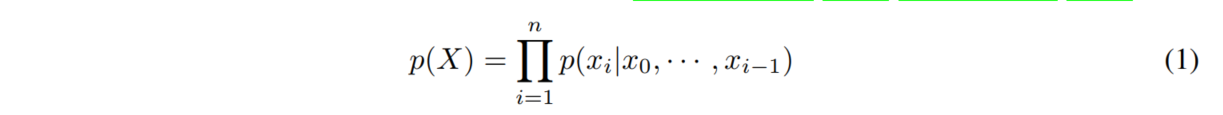
本文中,我们使用Transformer进行语言分布的建模。令$H_t=[(K_t^{(1)},V_t^{(1)}),...,(K_t^{(l)},V_t^{(l)})]$为由key-value组成的历史矩阵,从第i层0到t的时间序列。
3.2 STEERING GENERATION: ASCENDING $log p(a|x)$
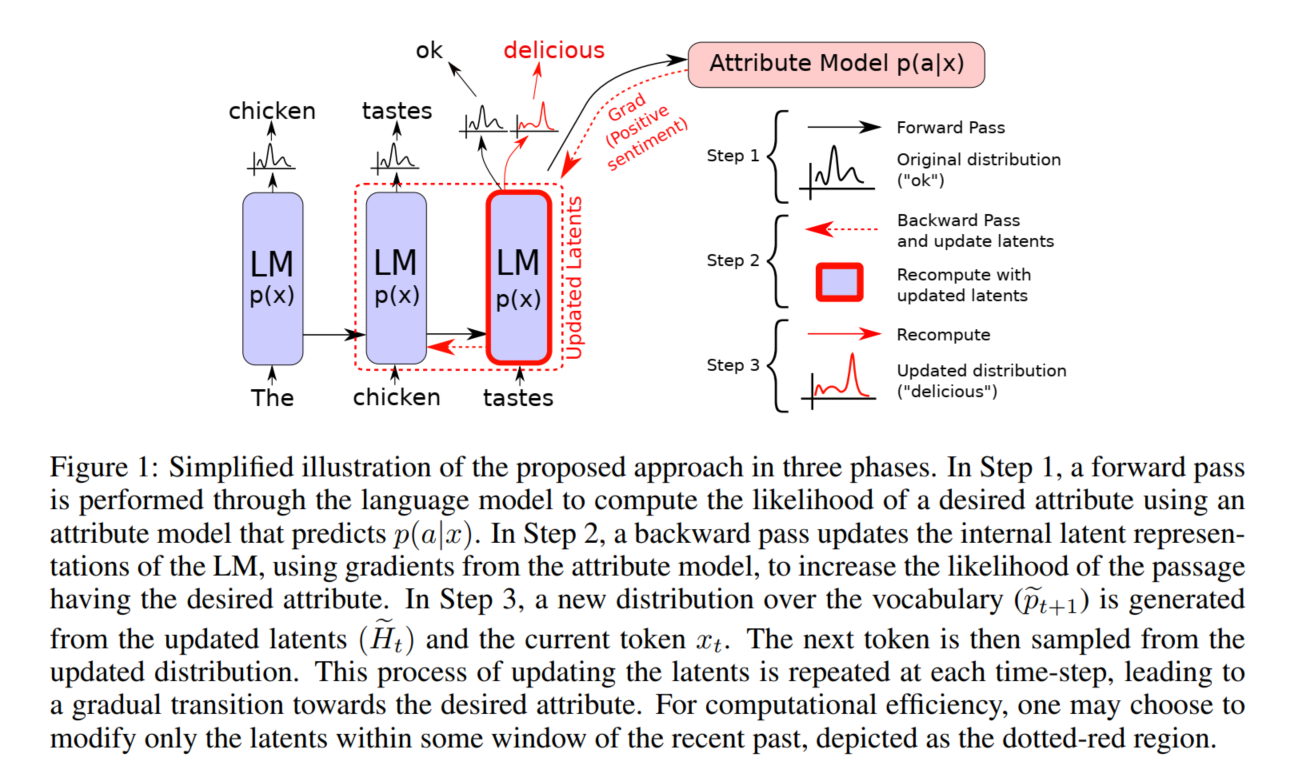
为了去控制语言模型的输出,在每个生成步t,我们转移历史$H_t$在两个梯度方向上,一种倾向于在条件属性模型$p(a|x)$下,更高的对数似然属性a;另一种是倾向于未修改语言模型p(x)的更高对数似然。将这些因素与可变乘数结合起来,为我们提供了一个可控的“旋钮”,以指定的强度在给定的情感方向上引导生成。参数更新仅限于Ht,而不限于其他激活模型,因为未来的预测仅通过Ht依赖于过去(注意,Ht由在时间t之前生成的所有Tramsformer的key-value组成)。在Ht空间经过每一步会导致模型激活的逐渐变化——这可能被认为是对过去的逐渐重新解释——从而引导下一代朝着理想的方向发展。
将∆Ht作为对Ht的更新,这样,使用(Ht+∆Ht)生成的文本会改变生成文本的分布,从而更可能拥有所需的属性。∆Ht初始化为零,并使用属性模型的梯度进行更新,该属性模型测量生成的文本具有所需属性的程度(例如正性)。我们重写属性模型$p(a|x)$为$p(a|Ht+∆Ht)$然后基于以下公式去更新∆Ht:

3.3 ENSURING FLUENCY: ASCENDING $log p(x)$
上一节中描述的方法能够生成针对特定判别器的文本,但如果不加以检查,当文本进入低概率区域时,将很快导致不切实际的敌对或愚蠢的示例(Szegedy et al.,2013;Nguyen et al.,2015)。为了解决这个问题,我们从两个方面使用了无条件语言模型,以确保流利度保持在或接近无条件语言模型的水平(这里是GPT-2)。
Kullback–Leibler (KL) Divergence
除了上述步骤之外,我们还更新∆Ht以最小化修改和未修改语言模型的输出分布之间的KL差异。实际中,这是通过在使用渐变之前将数量相加来实现的,尽管可以将其可视化为两个单独的步骤,如图2所示。我们用一个标量λKL来缩放KL系数,在实践中,将这个超参数设置为0.01通常可以很好地在各种任务工作。
Post-norm Geometric Mean Fusion
除了KL散度,我们还是用了后范数融合方法,这并不直接影响∆Ht;相反,它只是将生成的文本与无条件的p(x)LM分布联系起来。
3.4 SAMPLING AND RANKING
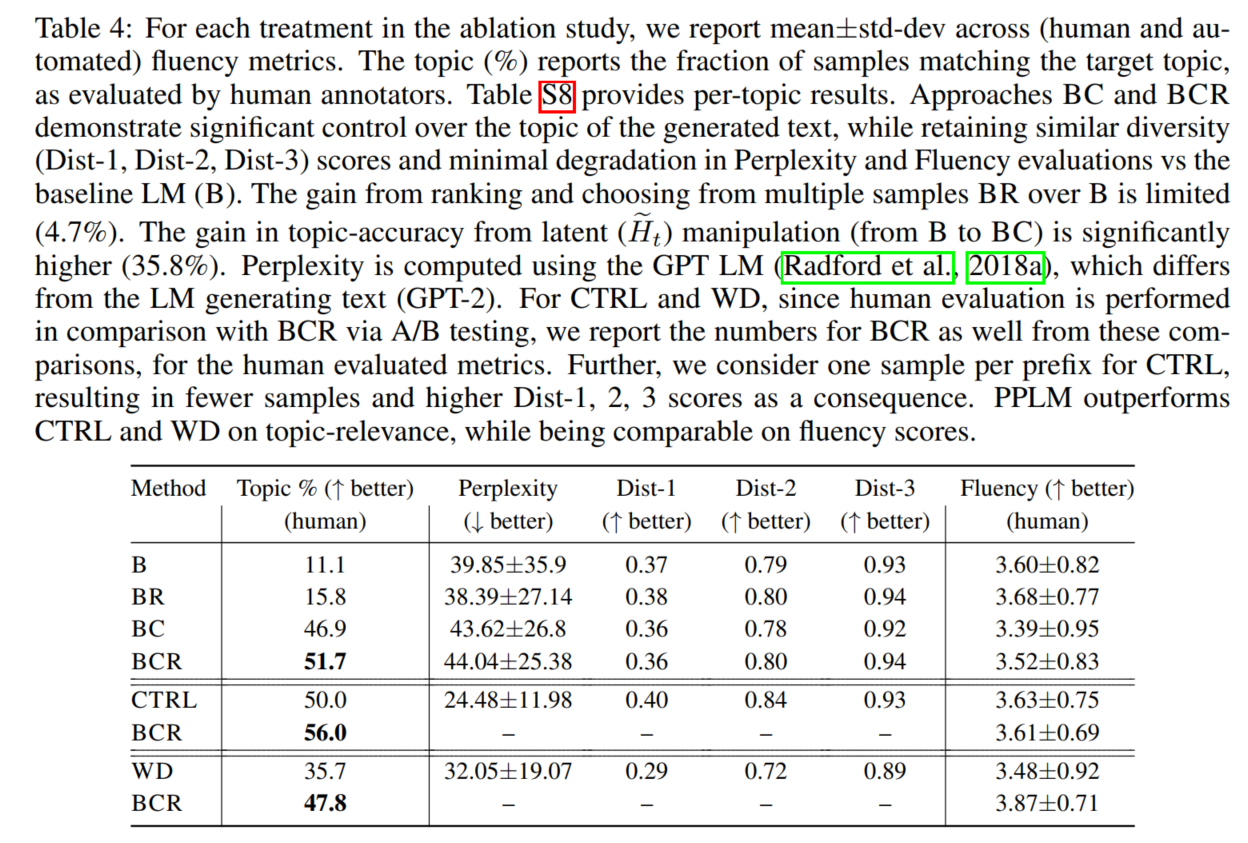
PPLM中的属性模型$p(a|x)$提供两种功能:首先,基于对数似然提供一个能排序想要样本的分数;其次,在潜在空间中执行更新的梯度上升方向。前者可用于生成r个样本,并对其进行排序,以选择最佳样本。除了使用更新的采样外,这还可以作为属性控制的附加方法。此外,为了避免重复性、低质量文本的问题(Holtzman et al.,2018),我们计算Dist-1、Dist-2和Dist-3分数的平均值(对于生成的文章),这是重复性的指标(Li et al.,2015),然后丢弃平均分数低于阈值τ的样本。
4 EXPERIMENTS, RESULTS, AND EVALUATION
4.1 EVALUATION METHODS AND ABLATION STUDY
我们评估两个属性:PPLM是否生成满足所需属性(主题或情感)的文本,以及当我们加强对属性的控制时,其文本质量是否恶化。注:我们可以随时将控制旋钮调低到零,以禁用属性控制,并达到原始模型的流畅性。如果需要,用户可以在推理时调整旋钮,直到在属性强度和流利性之间达到所选择的折衷。我们使用自动方法和人工注释器进行评估

4.2 BoW ATTRIBUTE MODELS
BoW的一些结果
4.3 DISCRIMINATOR ATTRIBUTE MODELS
当仅用BoW一些词难以表示的属性词,就可以使用判别器来进行属性控制。我们在输入句子x和相应标签yx的数据集上训练鉴别器,以下是结果。

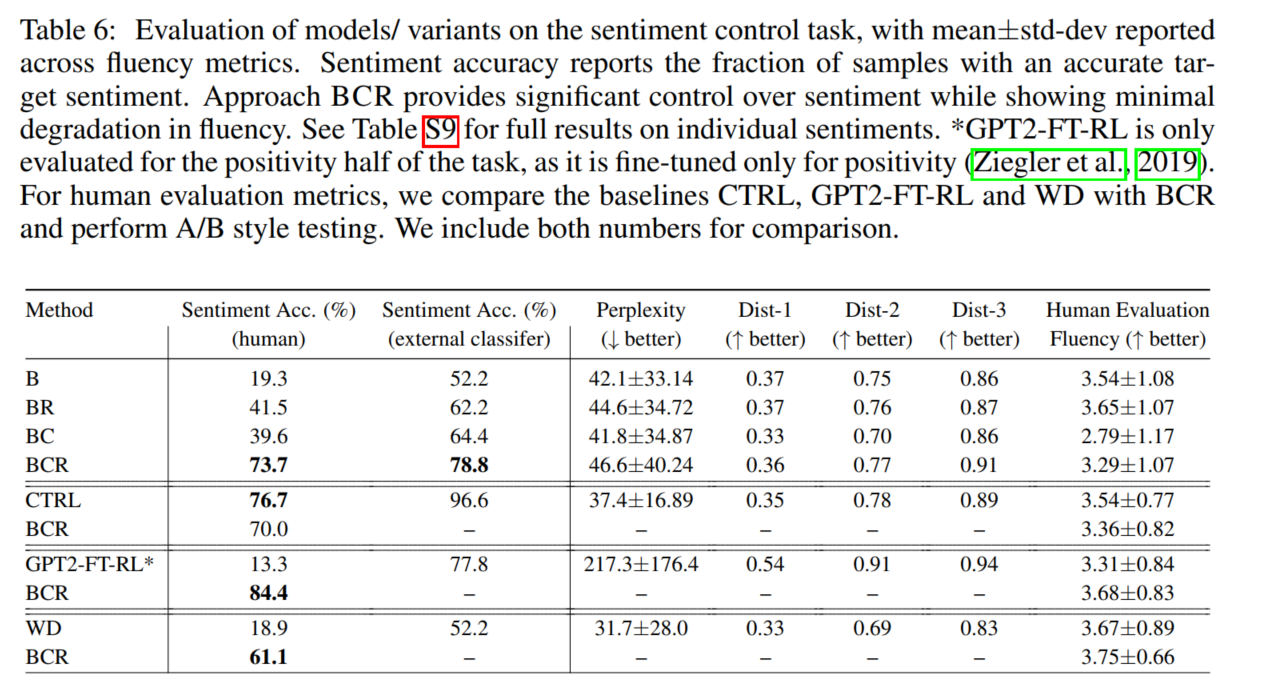
4.4 LANGUAGE DETOXIFICATION
使用大量互联网数据训练的语言模型反映了数据中存在的偏见和歧视。Wallace et al.(2019)最近的一篇论文进行了对抗性攻击,当给定一个经过仔细优化的触发器字符串作为前缀时,GPT-2会产生种族主义输出。他们还发现,当简单地使用“黑人”作为前缀时,2%的GPT-2样本包含明显的种族歧视。其他前缀(如“亚洲人”或“犹太人”)被提及,但没有报告百分比。我们进行实验并报告基线毒性百分比为10%(“亚洲人”)、12%(“犹太人”)和8%(“黑人”)。Wallace等人(2019年)发布的代码库产生了对抗性触发,平均毒性百分比为63.6%。更多细节见第S13节。
通过引入毒性分类器作为属性控制模型,并用负梯度更新潜在空间,PPLMs可以很容易地适应语言解毒。我们对来自毒性评论分类挑战(Jigsaw)的毒性数据训练了一个单层分类器,并表明与其他PPLM-Discrim方法具有相似的超参数设置,它在自然提示和对抗性触发条件下都能很好地工作。自然诱发的毒性百分比分别为6%、4%和10%,而对抗性诱发的毒性百分比则急剧下降到平均4.6%,具有统计学意义。注释程序和百分比和p值的完整表格的详细信息见表S23和第S13节。请注意,解毒语言的模型也可能被恶意用于生成有毒语言,这是我们在第S6节中简要讨论的主题
4.5 CONTROLLED STORY WRITING
我们探索辅助性故事写作的受控生成(Peng et al.,2018;Luo et al.,2019;Yao et al.,2019;Fan et al.,2018)。使用不受控制的LMs辅助艺术创作可能很困难。为了有助于结构,我们使用了预先定义的故事骨架,通常用于即兴创作。我们用PPLM填充这些前缀之间的空白。见表S20和表S21中的示例。

5 CONCLUSION
我们提出了PPLM,一个即插即用的方法可控的语言生成,容易组合到一个巨大的预训练LM和一个BoW模型,或者一个轻量级的容易去训练的判别器。PPLM实现了对属性的细粒度控制通过一个简单的基于梯度的采样机制。由于PPLMs在保持流利性的同时能够灵活地控制生成,因此它在支持下一代语言模型方面具有很大的潜力。