
论文链接
Abstract
本文主要研究基于非平行文本的文体转换。这是一个包括机器翻译、破译和情感改写在内的一系列问题的例子。关键的挑战是将内容与风格等其他方面分开。我们假设一个共享的潜在内容分布在不同的文本语料库中,并提出了一种利用潜在表达的精确对齐来进行风格转换的方法。从一个语体转换过来的句子应该和从另一个语体转换过来的例句相匹配。我们证明了这种交叉比对方法在三个任务上的有效性:情感改写、单词替换密码的破译和词序恢复。
1 Introduction
机器翻译、文本摘要类似的任务需要大量的平行语料进行训练,但是在一些NLP生成任务中,我们仅有非平行或单语言的数据。类似于文本破译或者风格迁移,在这些任务中,我们必须保留源语句的内容,但要使语句与所需的表示约束(例如,样式、明文/密文)保持一致。
我们的任务较有挑战性:我们只假设访问两个句子的语料库,尽管呈现的风格不同,但内容分布相同。我们的目标是证明这种内容的分布等价性,如果仔细加以利用,就足以让我们学会将一个文体中的句子映射到一个文体无关的内容向量,然后将其解码成一个内容相同但文体不同的句子。
本文中,我们提出了一个精细的句子级表示对齐方法在文本语料之间。我们通过学习一个编码器,它以一个句子和它的原始样式指示符作为输入,并将其映射到与样式无关的内容表示。然后将其传递给与样式相关的解码器进行渲染。实际上,更丰富的潜在内容表示更难在整个语料库中对齐,因此它们提供了更多的信息内容约束。此外,我们从交叉生成(风格转换)的句子中获取额外的信息,从而得到两个分布对齐约束。例如,风格转换成否定句的肯定句,作为一个总体,应该与给定的否定句相匹配。我们在图1中说明了这种交叉对齐

我们使用三个NLP任务去证明我们方法的有效性:情感改写、文本破译和词序恢复。在这三个任务中,模型都是使用非平行语料进行训练。
2 Related Work
Style transfer in vision 抽取内容和风格特征等,使用GANS network(CoupledGANs、CycleGAN)。虽然我们的方法具有类似的高级体系结构,但自然语言的离散性不允许我们重用这些模型,因此需要开发新的方法。
Non-parallel transfer in natural language在NLP中的生成任务大多需要平行语料,类似于(机器翻译、摘要生成等)。我们的方法很接近于不使用平行语料,但是使用训练中的非直接信号进行辅助。(VAEs,操作隐状态的表示以控制对应的情感生成等)。虽然我们的模型建立在分布式交叉对齐的基础上,以实现风格转换和内容保留,但可以以相同的方式添加约束。
Adversarial training over discrete samples最近离散样本中的对抗训练,大多使用RNN。在我们的工作中,我们采用了Professor-forcing算法(Lamb等人,2016年),该算法最初是为了弥补教师在训练过程中的强迫和测试过程中的自我反馈之间的差距。这样的设计符合我们的风格迁移场景which called cross-alignment。
3 Formulation


这个命题基本上是说不同风格生成的X应该足够“独特”,否则风格之间的转换任务就没有很好的定义。虽然这看起来微不足道,但即使对于简单的数据分布,它也可能不适用。下面的例子说明了在不同的模型假设下,转移(和恢复)是如何变得可行或不可行的。正如我们将看到的,对于某一风格的Y,z的分布越复杂,恢复传递函数的可能性就越大,寻找传递函数就越容易。
3.1 Example 1: Gaussian

3.2 Example 2: Word substitution
这里考虑另一个例子,当z是一个双语语言模型,风格y是一个正在使用的词汇表,它将每个“内容词”映射到它的表面形式(词汇形式)。如果我们观察同一语言z的两个实现x1和x2,那么转移和恢复问题就变成了推断x1和x2之间的单词对齐。
这就是一个简单的语言破译或者翻译版本。除此之外,回复问题仍然是很困难的。为了解释这一问题,假设$M_1$和$M_2$是$X_1$和$X_2$的概率估计,寻找单词对齐与去寻找一个排列矩阵P,满足$P^TM_1P≈M_2$是相似的,可以表示为一个优化问题:
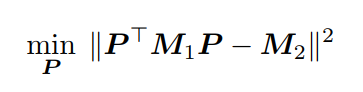
同样的公式适用于给定M1和M2作为两个图的邻接矩阵的图同构(GI)问题,表明确定P的存在性和唯一性至少是GI困难的。幸运的是,如果M作为一个图足够复杂,那么搜索问题可能更容易处理。例如,如果作为一个集合的每个顶点的关联边的权重是唯一的,那么可以通过简单地匹配边集合来找到同构。这个假设在很大程度上适用于我们的场景,其中z是一个复杂的语言模型。我们在结果部分以经验证明了这一点。
上述例子表明,作为潜在内容变量的z应该承载最复杂的数据x,而作为潜在风格变量的y应该具有相对简单的效果。我们将在下一节中相应地构建模型。
4 Method
由于图像中的数据是连续的,所以可以直接进行迁移学习,由于自然语言的离散性,我们不能直接进行训练;需要我们在潜在空间进行操作。由于x1和x2是给定潜在内容变量z之后条件独立。

这样表示建议我们使用一个自编码模型,特别地,一个风格迁移任务将x2迁移到x1涉及到两步:编码步和解码步。编码步骤负责推断x2的内容$z-p(z|x_2,y_2)$:解码步骤负责:生成对应的迁移事务从$p(x_1|y_1,z)$,本文中,我们使用神经网络近似学习和训练$p(z|x,y)$和$p(x|y,z)$。

正如我们的生成框架所设想的那样,为了使翻转风格成为一个有意义的迁移,$X_1$和$X_2$的内容空间必须是连续的。为了限制x1和x2是从相同的潜在内容分布p(z)生成的,一种选择是应用可变自动编码器(Kingma和Welling,2013)。VAE先使用一个先验的概率密度$p(z)$,例如$z-N(0,I)$,然后使用KL散度去标准化后验$p_E(z|x_1,y_1)$和$p_E(z|x_2,y_2)$
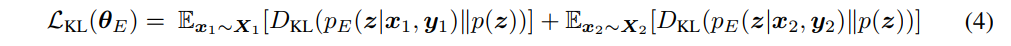
然而,正如我们在上一节中所讨论的,将z限制为简单且均匀的分布,并将大部分复杂性推给解码器,对于非并行数据的风格迁移可能不是一个好的策略。相比之下,标准的自动编码器只是将重建误差最小化,鼓励z携带尽可能多的x信息。另一方面,它降低了p(x|y,z)中的熵,这有助于在y1和y2之间切换时产生有意义的风格转换。在不显式建模p(z)的情况下,仍然可以强制p(z|y1)和p(z|y2)的分布对齐。为此,我们介绍了自动编码器的两种受约束的变体。
4.1 Aligned auto-encoder
省去了对p(z)作显式假设并使后验值与p(z)一致的VAEs,我们将$p_E(z|y_1)$和$p_E(z|y_2)$相互对齐,从而得到如下约束优化问题。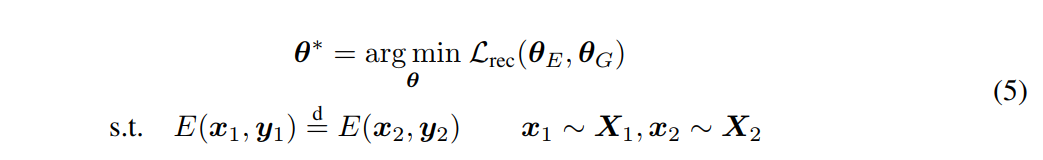
在实践中,拉格朗日松弛的原始问题,而不是优化。我们引入了一个对抗性鉴别器D来校准不同类型z的聚集后验分布(Makhzani et al.,2015)。D旨在区分这两种分布:
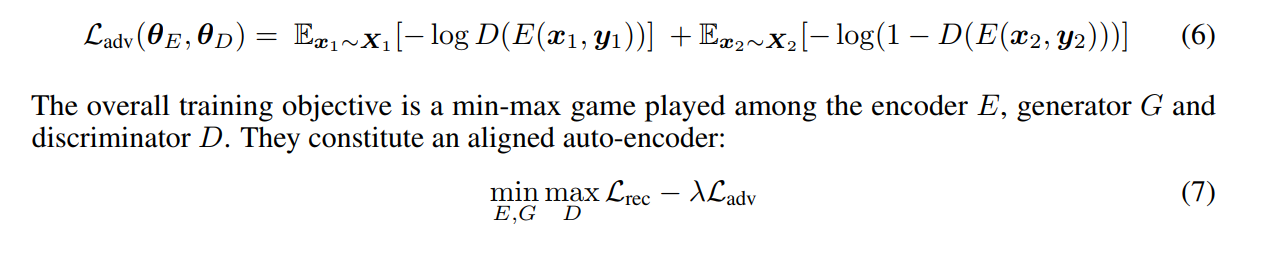
我们使用带有GRU单元的单层RNNs来实现编码器E和生成器G。E获取一个初始隐藏状态为y的输入句子x,并输出最后一个隐藏状态z作为其内容表示。G生成一个以潜在状态(y,z)为条件的句子x。为了对齐$z_1=E(x_1,y_1)$和$z_2=E(x_2,y_2)$的分布,鉴别器D是具有单个隐藏层和sigmoid输出层的前馈网络。
4.2 Cross-aligned auto-encoder
第二种变体是交叉对齐自动编码器,它直接将一种风格的迁移样本与另一种风格的真实样本对齐。
在生成性假设下,$p(x_2|y_2)=\int_{x_1}p(x_2|x_1;y_1;y_2)p(x_1|y_1)dx_1$,因此x2(从左侧取样)应表现出与被迁移的x1(从右侧取样)相同的分布,反之亦然。与我们的第一个模型类似,第二个模型使用两个判别器D1和D2来排列群体。D1的任务是区分真实x1和被迁移的x2,D2的任务是区分真实的x2和被迁移的x1。
对抗训练由G生成的离散样本由于梯度阻断无法进行反向传播,虽然很多人使用强化学习,但由于高方差的采样梯度导致收敛并不稳定。首先,我们不使用单个采样词作为生成器RNN的输入,而是使用词上的softmax分布。具体地说,在从G(y1,z2)迁移x2的生成过程中,假设在时间步t处输出logit向量是vt。我们将其峰值分布softmax(vt/γ)作为下一个输入,其中γ是温度参数。
其次,我们使用Professor Forcing(Lamb et al.,2016)来匹配隐藏状态序列,包含输出信息且平滑分布的输出词。也就是说,到判别器D1的输入是由实例x1强制的(1)G(y1;z1)教师的隐藏状态序列,或者由先前的软分布自馈的(2)G(y1;z2)教师的隐藏状态序列。
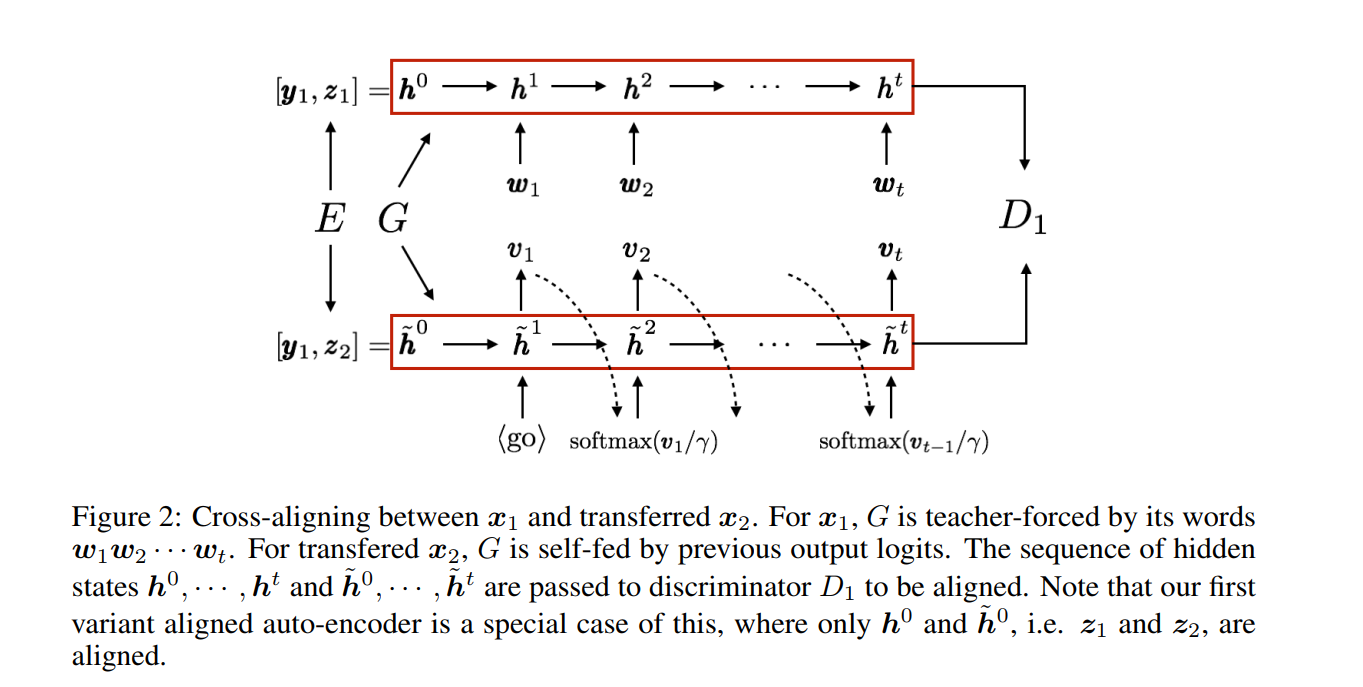

交叉对齐自动编码器的运行过程如图2所示。注意,交叉对齐加强了潜在变量z在生成器G的递归网络上的对齐。通过对齐整个隐藏状态序列,它可以防止z1和z2的初始不对齐在递归生成过程中传播,因此转移的句子可能会结束在远离目标的某个地方目标域。
我们使用卷积神经网络实现D1和D2序列分类(Kim,2014)。算法1给出了训练算法。
5 Experimental setup
Sentiment modification 我们的第一个实验是以改变潜在情绪为目标的文本改写,这可以看作是否定句和肯定句之间的风格转换。我们在Yelp餐厅评论上进行实验,利用与每个评论相关的现成用户评分。按照标准惯例,评分高于三分的评审被认为是积极的,低于三分的评审被认为是消极的。当我们的模型在句子层次上运行时,数据集中的情感注释在文档层次上提供。我们假设文档中的所有句子都有相同的情感。这显然过于简单化了,因为有些句子(例如背景)是情绪中立的。考虑到这样的句子在长评论中更为常见,我们过滤掉超过10句的评论。我们进一步过滤剩下的句子,去掉那些超过15个单词的句子。结果数据集有25万个否定句和35万个肯定句。将出现少于5次的单词替换为“
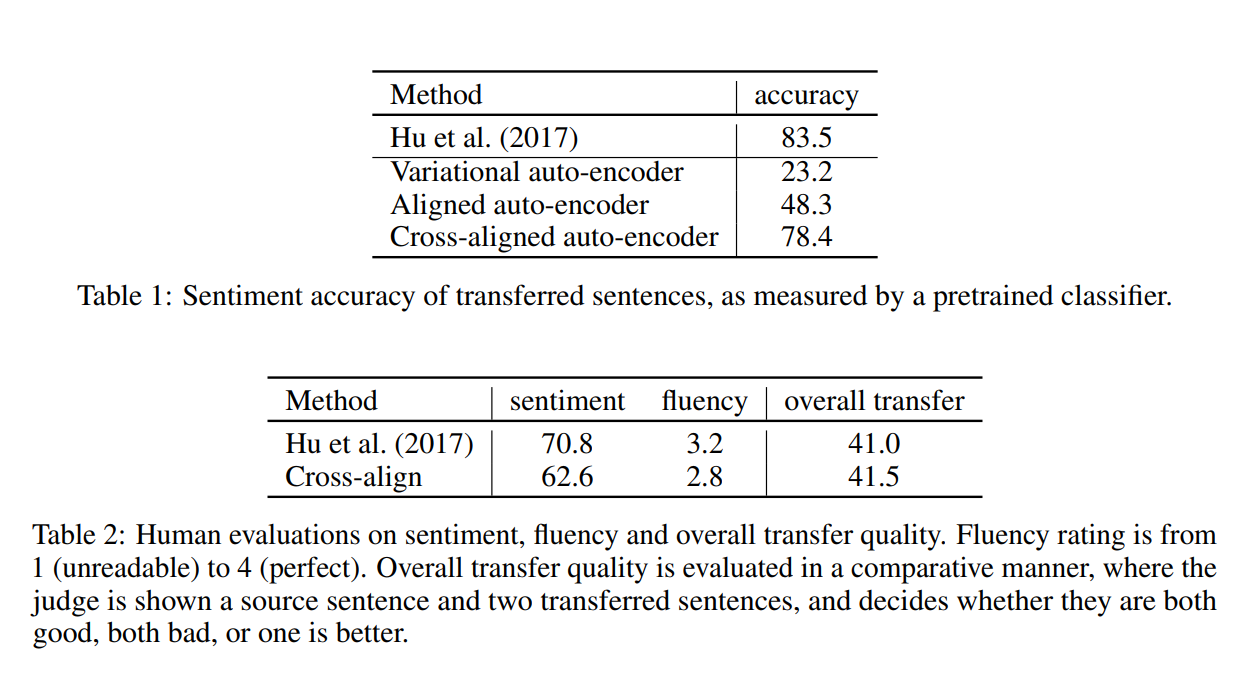
为了定量评估转换的句子,我们采用了一种基于模型的评估标准,类似于用于图像传输的评估标准(Isola et al.,2016)。具体地说,我们根据预先训练好的情感分类器来衡量一个转移句有多少正确的情感。为此,我们使用Kim(2014)中描述的TextCNN模型。在我们简化的风格转换数据集上,它几乎达到了97.4%的完美准确率。
虽然定量评估提供了一些传输质量的指标,但它并没有涵盖这一代任务的所有方面。因此,我们还对从测试集2中随机选取的500个句子进行了两次人类评估。在第一次评估中,评委们被要求根据句子的流畅性和情感程度对生成的句子进行排名。流利程度从1分(不可读)到4分(完美),而情感类别是“积极”、“消极”或“两者都不是”(可能是矛盾的、中性的或无意义的)。在第二个评价中,我们对转移过程进行了比较评价。以随机顺序向注释者展示源句和系统的相应输出,并询问“哪一个转移句在语义上等同于具有相反情感的源句?”?”. 它们可以都令人满意,A/B更好,也可以都不令人满意。我们为每个问题收集两个标签。标签协议和冲突解决策略可在补充材料中找到。请注意,这两个评估不是多余的。例如,一个系统总是独立于源句生成语法正确、情感正确的句子,在第一个评估设置中得分较高,但在第二个评估设置中得分较低。
Word substitution decipherment
我们的第二组实验涉及字词替换密码的破译,这在NLP文献中已有探讨(Dou和Knight,2012;Nuhn和Ney,2013)。这些密码将明文(自然语言)中的每个单词根据1:1替换密钥替换为密码令牌。解密任务是从密文中恢复明文。如果我们能够访问并行数据,这任务是微不足道的。然而,我们有兴趣考虑一个非并行破译方案。为了训练,我们选择200K个句子作为X1,并对不同的200K个句子集应用替换密码f得到X2。虽然这些句子是非平行的,但它们是从评论数据集中的相同分布中提取的。开发集和测试集有100K个平行句D1和D2。我们可以使用Bleu分数定量比较D1和转移(解密)D2(Papineni et al.,2002)。
显然,这个破译任务的难度取决于替换词的数量。因此,我们根据替换词汇表的百分比来报告模型性能。注意,转移模型不知道f是一个词替换函数。他们完全从数据分发中学习。
除了有不同的迁移模型外,我们还引入了一个简单的基于词频的解码基线。具体来说,我们假设X1和X2之间共享的单词不需要翻译。其余的单词根据频率进行映射,任意断开连接。最后,为了评估任务的难度,我们报告了在平行语料库上训练的机器翻译系统的准确性(Klein et al.,2017)。
Word order recovery
我们最后的实验集中在单词排序任务,也称为bag翻译(Brown et al.,1990;Schmaltz et al.,2016)。通过学习原始英语句子X1和混叠英语句子X2之间的语体迁移函数,该模型可以用来恢复混叠句子的原始语序(或者反过来随机排列句子)。非平行训练数据和平行测试数据的构造过程与单词替换破译实验相同。同样,传输模型不知道f是一个随机函数,完全从数据中学习
6 Results

7 Conclusion
之前的迁移学习都是使用平行语料,本文工作中,我们将其定义为翻译问题,并使用非平行的语料。我们的方法使用强制的分布表示对齐去优化神经网络,我们使用情感迁移任务、文本破译、单词排序等任务证明我们方法的有效性。本文也引出了一个问题:when can the
joint distribution p(x1; x2) be recovered given only marginal distributions?,我们认为解决此问题可以促进情感迁移在CV和NLP中的发展。