
论文链接
Abstract
本文专注于细粒度的情感迁移(FGST),该任务的目标是在保留原始语义内容的同时,修改输入序列以满足给定的情感强度。不同于传统的情绪传递任务,它只反转文本的情绪极性(正/负),FTST任务需要更细致和细粒度的情绪控制。为了解决这个问题,我们提出了一个新的Seq2SentiSeq模型。具体地,通过高斯核层将数字情感强度值并入解码器以精细地控制输出的情感强度。此外,针对并行数据不足的问题,提出了一种循环强化学习算法来指导模型训练。在这个框架中,精心设计的奖励可以平衡情感转换和内容保存,同时不需要任何ground truth的输出。实验结果表明,该方法在自动评价和人工评价方面均优于现有方法。
1 Introduction
为了对文本生成进行更细致、更精确的情感控制,我们转向细粒度文本情感转移(FTST),它在保持语义内容不变的情况下,修改一个序列以满足给定的情感强度。例子如下:
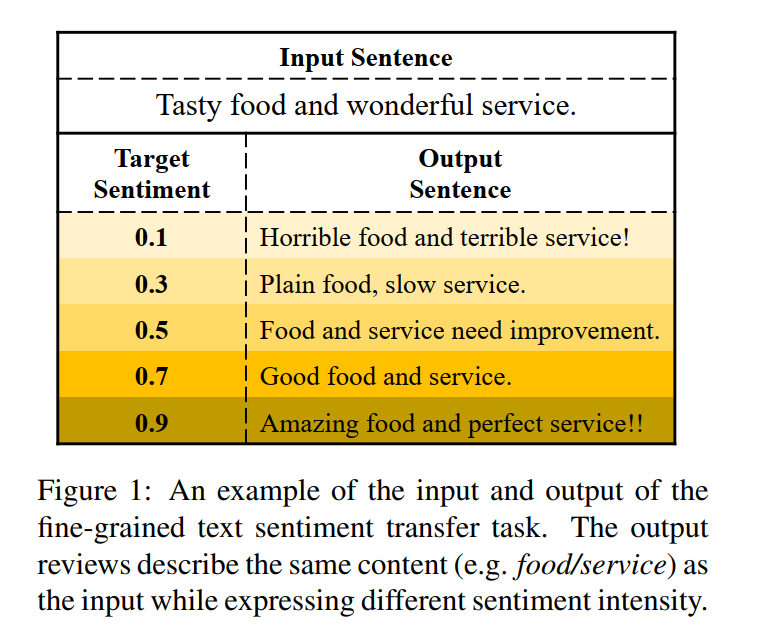
FTST任务有两个主要挑战。首先,在生成句子时很难实现情感强度的细粒度控制。以前关于粗粒度文本情感迁移的工作通常对每个情感标签使用单独的解码器(Xu et al.,2018;Zhang et al.,2018b)或将每个情感标签嵌入单独的向量(Fu et al.,2018;Li et al.,2018)。然而,这些方法对于细粒度文本情感迁移是不可行的,因为目标情感强度值是一个实际值,而不是离散的标签。第二,平行数据在实践中是不可用的。换句话说,我们只能访问标有细粒度情绪评级或强度值的语料库。因此,在FTST任务中,我们不能通过ground truth输出来训练生成模型。
针对上述两大挑战,我们提出了两个相应的解决方案。首先,为了控制生成句子的情感强度,我们提出了一种新的情感强度控制序列对序列(Seq2Seq)模型Seq2SentiSeq。它通过高斯核层将情感强度值引入到传统的Seq2Seq模型中。通过这种方式,该模型可以鼓励在解码过程中生成情感强度接近给定强度值的词。其次,由于缺乏并行数据,我们不能直接用极大似然估计(MLE)对模型进行训练。因此,我们提出了一种循环强化学习算法来指导模型训练,而不需要任何并行数据。设计的奖励可以平衡情感迁移和内容保存,同时不需要任何地面真相输出。
本文主要贡献如下:
- 提出了一种情感强度控制的生成模型Seq2SentiSeq,通过高斯核层引入情感强度值,实现对生成句子的细粒度情感控制。
- 为了适应非并行数据,我们设计了一种循环强化学习算法CycleRL来指导模型的无监督训练。
- 实验表明,该方法在自动评价和人工评价两方面均优于现有系统。
2 Proposed Model
2.1 Task Definition
给定一个输入序列x和一个目标情绪强度值$v_y$,FTST任务的目标是生成一个序列y,该序列y不仅表达了目标情绪强度$v_y$,而且保留了输入x的原始语义内容。在不损失通用性的前提下,我们将情绪强度值$v_y$限制在0(最负)到1(最负)之间阳性。
2.2.1 Encoder
使用双向RNN对句子进行编码,获取每个词的表示$h_i$。
2.2.2 Decoder
给定输入句子的隐层表示$\{h_i\}_{i=1}^m$和目标情感强度值$v_y$,decoder目标去生成序列y,不仅与x描述相同的语义,同时表达出了情感$v_y$。
为了在解码过程中达到控制情感的目的,我们首先在原有的语义表示之外,在每个词中嵌入一个额外的情感表示。语义表征表征词的语义内容,情感表征词表征情感的强度。形式上,解码器在时间步t的隐藏状态st计算如下:
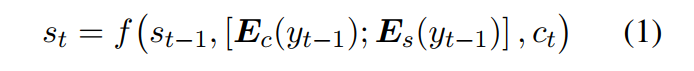

与传统的Seq2Seq模型(Bahdanau et al.,2014)类似,整个词汇表的语义概率分布计算如下
情绪概率度量生成序列的情绪强度与目标vy的接近程度。通常,每个词都有特定的情感强度。例如,单词“好”的强度约为0.6,“好”的强度约为0.7,“好”的强度约为0.8。然而,当涉及到之前生成的词时,当前生成词的情感强度可能完全不同。例如,短语“不好”的负强度约为0.3,而“非常好”的负强度约为0.9。也就是说,每个词在时间步t的情感强度应该由情感表示$E_s$和当前解码器状态$s_t$两者决定。因此,我们定义了一个情感预测的函数$g(E_s,s_t)$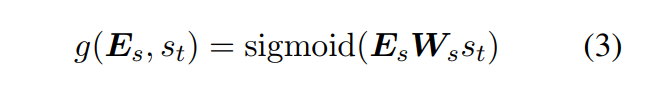
直观地说,为了实现情感的细粒度控制,情感强度更接近目标情感强度值$v_y$的词应该被赋予更高的概率。
受Luong et al.(2015)和Zhang et al.(2018a)的启发,为了支持情感强度接近vy的词,我们引入了一个高斯核层,该层以vy为中心放置高斯分布。具体而言,情绪概率表示为:
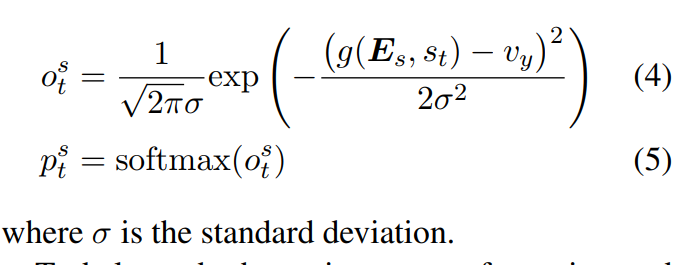
为了平衡情感转换和内容保存,将整个词汇表的最终概率分布pt定义为两个概率分布的混合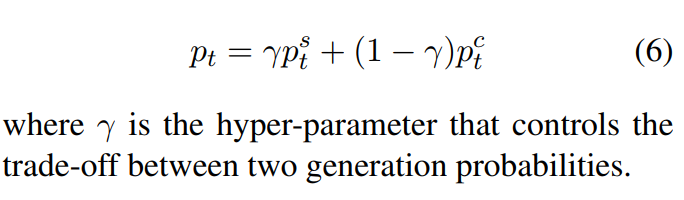
2.3 Training: Cycle Reinforcement Learning
FTST任务的一个严重挑战是缺乏并行数据。由于ground truth输出y是不可观测的,因此不能直接用极大似然估计(MLE)进行训练。为此,我们设计了一种循环强化学习(CycleRL)算法。算法1概述了训练过程。两个奖励旨在鼓励改变情绪,但保留内容,而不需要平行数据。下面介绍Seq2SentiSeq模型的两个奖励和相应的梯度的定义。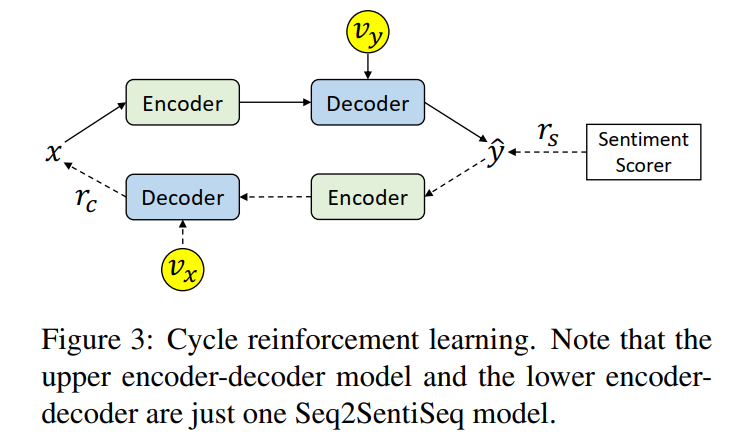
2.3.1Reward Design
我们为FTST的两个目标(sentiment transformation and content preservation)分别设计两个rewards,然后使用一个全局reward r去平衡两个目标和指导模型训练。
Reward for sentiment transformation.
一个预先训练的情感评分器用来评估样本句子$\hat{y}$与目标情感强度值$v_y$的匹配程度。具体而言,情绪转化的回报公式如下:
Reward for content preservation.
直观地说,如果模型在内容保存方面表现良好,则很容易对源输入x进行反向重构。因此,我们将内容保存的报酬设计为基于生成的文本$\hat{y}$和源情感强度值$v_x$的模型重构x的概率。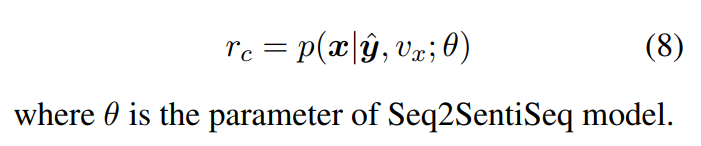
Overall reward.
最终整体的reward。
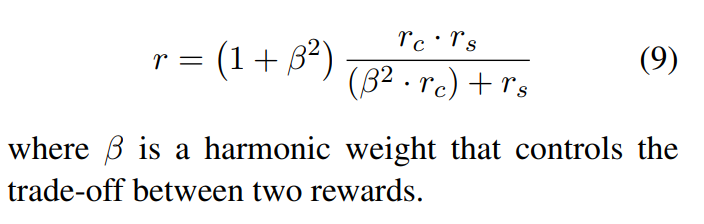
3 Experimental Setup
3.1 Dataset
我们在Yelp数据集5上进行实验,该数据集包含大量的产品评论。每一篇评论都被分配了一个从1到5的情绪等级。由于细粒度评分中人与人之间的标签不一致更为严重,因此我们对Jaccard相似度大于0.9的句子进行平均评分。然后,将平均评级标准化为0到1之间的情绪强度。其他数据预处理同沈等(2017)。最后,我们得到了总共64万个句子。我们随机分为630k训练,10k验证,500k测试。尽管训练数据集的情绪强度分布不均匀,但该框架由一个均匀的数据扩充组成,该扩充生成的句子强度来自区间[0,1],步长为0.05,以指导模型训练(算法1中的步骤6)。
3.3 Baselines
细粒度系统旨在修改输入句子以满足给定的情感强度。Liao et al.(2018)构建伪平行语料库来训练一个模型,该模型是一个修正的VAE和一个耦合组件的组合,该组件对伪平行数据进行建模,并具有三个额外的损失L。此外,我们还考虑了SCSeq2Seq(Zhang等人,2018a),这是在对话生成中提出的一种特异性控制的Seq2Seq模型。为了适应这种无监督的任务,提出的CycleRL训练算法被用来训练SC-Seq2Seq模型。
粗粒度系统旨在反转输入的情绪极性(正/负),这可以被视为情绪强度设置为低于平均值(负)或高于平均值(正)的特殊情况。我们将我们提出的方法与以下最先进的系统进行了比较:CrossAlign(Shen et al.,2017)、MultiDecoder(Fu et al.,2018)、DeleteRetrieve(Li et al.,2018)和Unpaired(Xu et al.,2018)。
3.4 Evaluation Metrics
3.4.1 Automatic Evaluation
- Content (BLEU)
- Fluency (PPL)
- Sentiment
3.4.2 Human Evaluation
4 Results and Discussion
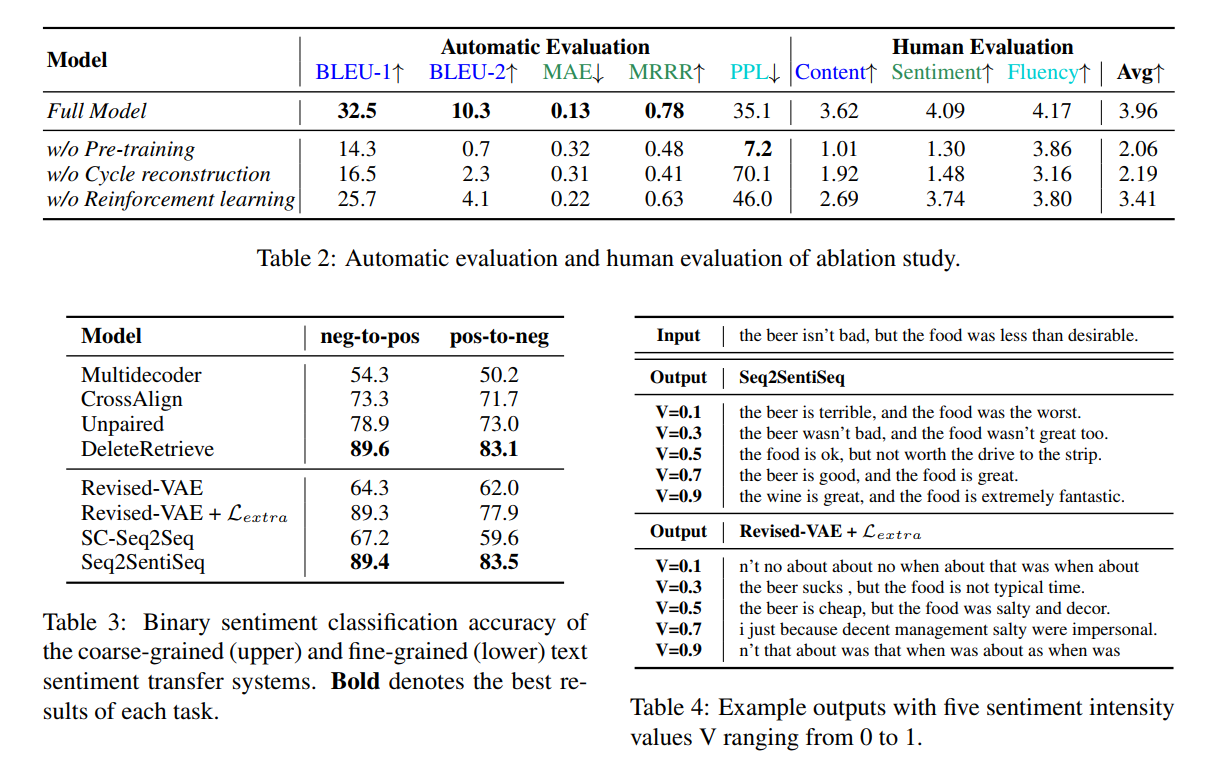
5 Related Work
近年来,关于无监督情绪传递的文献越来越多。这项任务的目的是翻转一个句子的情感极性,但保持其内容不变,没有平行数据。然而,对于情感的细粒度控制的研究却很少。Liao et al.(2018)通过启发式规则利用伪并行数据,从而将此任务转化为监督任务。然后提出了一种基于变分自动编码器(VAE)的模型,首先将内容因子和源情感因子分离,然后将内容因子和目标情感因子结合起来。然而,伪并行数据的质量并不理想,这严重影响了VAE模型的性能。与之不同的是,我们在训练过程中通过反译(Lample等人,2018b)动态更新伪并行数据(等式12)。
NLP的其他一些任务也对控制文本生成的细粒度属性感兴趣。例如,Zhang et al.(2018a)和Ke et al.(2018)提出控制对话生成的特异性和多样性。我们从这些文章中借鉴了一些想法,但我们的工作动机和提出的模式却与之相去甚远。主要区别在于:(1)由于情感依赖于局部语境,而特异性独立于局部语境,因此我们的模型中有一系列的设计来考虑局部语境(或先前生成的词)st(例如,公式1,公式3)。(2) 由于缺乏并行数据,我们提出了一种循环强化学习算法来训练所提出的模型(第2.3节)。
6 Conclusion
我们提出了一个Seq2SentiSeq模型来控制生成句子的细粒度情感强度。为了在没有任何并行数据的情况下训练所提出的模型,我们设计了一种循环强化学习算法。我们将所提出的方法应用于Yelp评论数据集,获得了自动评估和人工评估的最新结果。