
ABSTRACT (摘要)
重排是推荐系统中一项核心任务,重排目标是为用户最终提供一个有序列表。通常,一个排序模型使用已标记的数据集从全局最优角度,为每个结果打出一个分数。然而,这样的做法可能是排序次优解,因为打分函数仅对每个结果独立打分,没有显示考虑到结果与结果之间的相互影响、用户的偏好与意图也考虑欠佳。本文提出了个性化的重排模型( Personalized Re-ranking Model ,PRM),通过使用现有的排序特征向量,PRM可以方便地部属在任何精排模块之后。PRM使用Transfomer作为encoder,目标是直接优化推荐结果列表。采用Transfomer的一个原因是,其中的Self-attention模块直接对整个列表中任何一对结果之间的全局关系进行建模。同时本文也证实了,通过引入为预训练的embedding,学习个性化的encoder,可以进一步提升模型性能。在离线数据集与在线ab实验,PRM均取得了较大的提升。
1 INTRODUCTION (介绍)
通用的推荐系统中的排序只考虑user与item对的特征,而不考虑最终列表中其他item的影响,尤其是旁边的item。虽然pairwise、listwise已经使用了item-pair与item-list作为输入,但是它们只专注于使用点击类的标签数据来优化损失函数,并没有对item之间的相互影响进行显示地建模。
本文贡献
- 本文首次提出了一个推荐系统中的个性化重新排序问题,这是首次将个性化信息明确地引入到大规模在线系统中的重排任务。
- 使用基于个性化embedding与Transfomer的PRM模型结构计算最终重排分数。
- 发布了一个大规模的电商重排数据集。
- 离线与在线PRM均取得了显著的提升。
2 RELATED WORK (相关工作)
由于该文章当时为重排早期文章,当时重排相关工作主要还是基于GRU、LSTM等模型展开。
3 RE-RANKING MODEL FORMULATION (重排模型公式)
本文所用到的符号说明: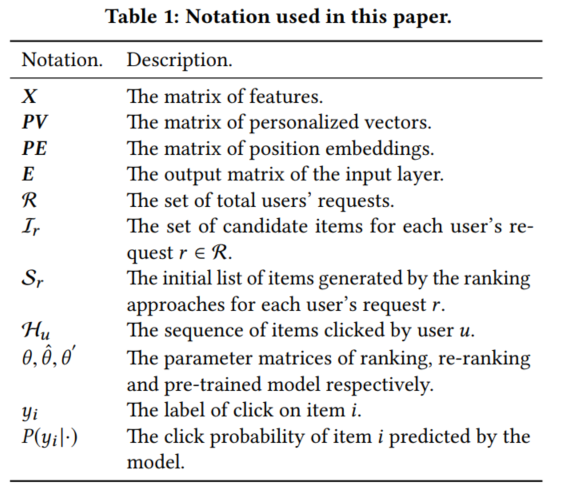
传统LTR优化目标为: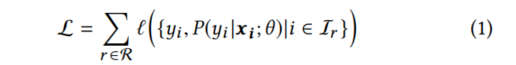
对照上面的表格,是能看懂该公式的。将item的特征$x_i$输入给模型,P为模型输出的概率,最终目标是最小化真实标签(点击/未点击)与模型预测概率之间的误差。
本文认为仅用$x_i$是不充分的,还需要考虑额外的信息:
- item-pair之间的影响
- user-item之间的交互
item-pair之间的影响通过原始的排序结果$S_r$可以直接学习到。然而很少的研究会对user与items之间的交互进行考虑,本文引入个性化矩阵$PV$去学习用户特定编码函数,该函数能够对item对之间的个性化相互影响进行建模。
本文重排模型建模目标为以下公式:

引入PV(个性化向量),仅对精排给出的列表中items进行优化排序结果。
4 PERSONALIZED RE-RANKING MODEL (个性化的重排模型 PRM)
4.1 Model Architecture(模型结构)
整体模型结构包含输入层、编码层、输出层。输入层为精排输入的item列表,输出层结果为重排之后的item列表。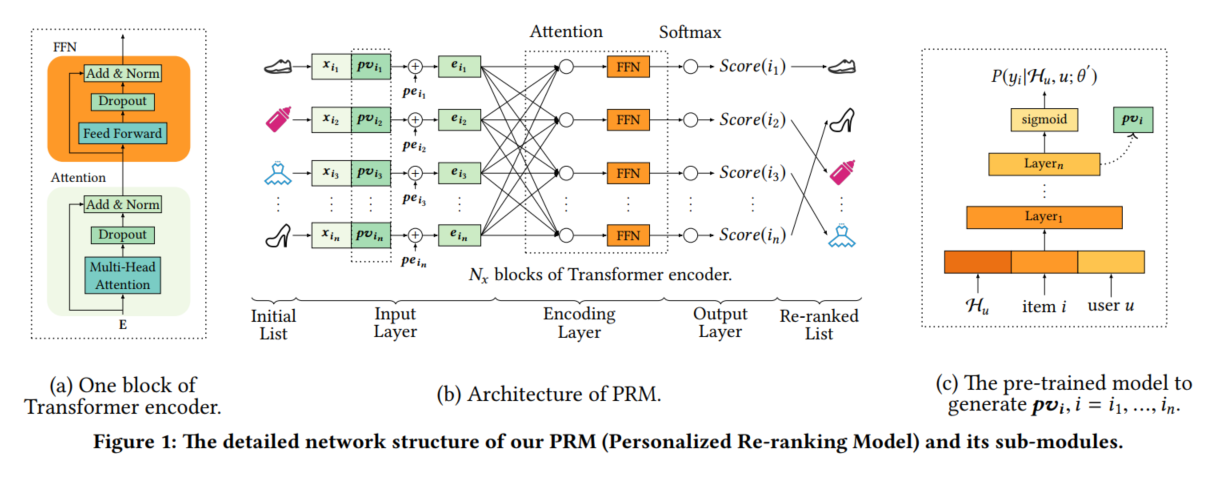
4.2 Input Layer (输入层)
Personalized Vector (PV ).个性化向量
尽管精排队列给出的列表已经有部分个性化结果了,但对于整个用户的个性化结果来说,还不够。本文拼接原始的特征向量X与用户个性化的向量PV(图1b),从而重排阶段引入用户个性化。
Position Embedding (PE).位置向量为了利用精排队列中的items的序列信息,本文引入位置编码向量PE(可学习),使用方式与[X;PV]+PE。
在输入向量之后使用FFN进行编码与维度转换,得到图1b中输入层最后的e。
4.3 Encoding Layer(编码层)
编码层目的是学习items对与额外信息(用户偏好、items初始列表)之间的交互(图1a)。本文使用N层Transformer进行编码,主要考虑到了TRM的并行,self-attention不会依赖item之间的距离等因素。
从图1a可以看出,本文使用的Transformer block与原论文基本一致,也是用到了Multi-head Self-Attention,FFN等结构。
4.4 Output Layer(输出层)
输出层目标是为每个item打出一个重排得分,此处最终使用softmax函数进行输出。输出结果为点击每个item的概率。
训练模型时,本文使用点击相关数据完成训练,最终损失函数为交叉熵。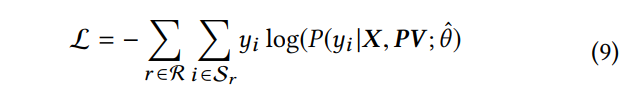
4.5 Personalized Module(个性化模块)
直观来说,可以直接用PRM来端到端学习用户个性化向量PV,然而在重排阶段学习PV,缺少了用户的通用偏好信息,因此本文使用预训练模型生成用户个性化向量(图1c)。输入为用户的点击序列items(H),当前item与用户user的信息(性别、年龄、购买力等),训练数据仍然使用点击数据。损失函数为二分类交叉熵。最终取sigmoid之前层网络的输出结果作为用户个性化向量PV。
由于是CTR任务,当然作者也建议使用FM、FFM、DeepFM、DCN、FFN、PNN等用来学习PV。
5 EXPERIMENTAL RESUTLS (实验结果)
数据集:
- Yahoo Letor dataset.
- E-commerce Re-ranking dataset. (本文提出)
Baselines:
- LTR模型:
- SVMRank,训练方式pairwise
- LambdaMart,训练方式listwise
- DNN-based LTR,训练方式pointwise
- Re-ranking模型
- DLCM,使用GRU去编码全局信息
- GlobalRerank,使用基于RNN、attention的decoder
- Seq2Slate,使用point network去生成重排列表
由于GlobalRerank、Seq2Slate时间复杂度高,无法并行处理,无法线上实时响应,本文重排模型仅使用DLCM作为基线对比。
Metrics:
- 离线
- Precision@k
- MAP@k
- 在线ab
- PV (items曝光数)
- IPV (items点击数)
- CTR (点击率)
- GMV (商品交易额)
结果
离线: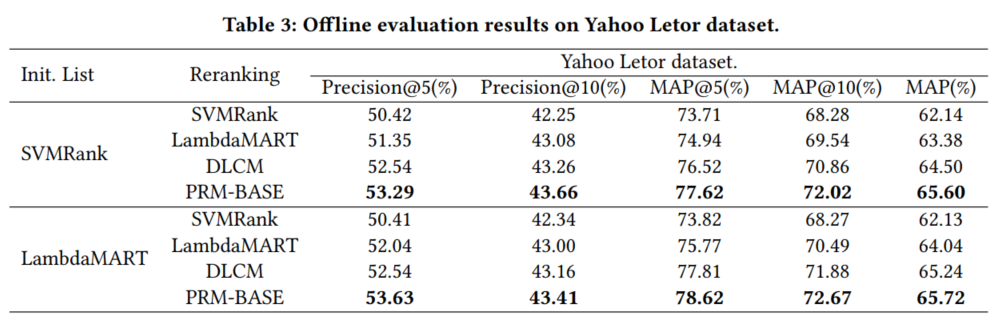
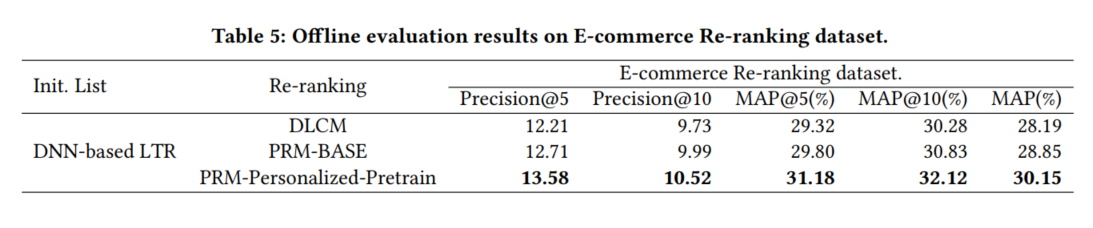
在线ab:
6 CONCLUSION AND FUTURE WORK
在读论文时,确实有个疑惑是PRM可能多样性考虑不足,这一点也是作者未来的展望,希望在学习重排结果时,不会破坏原有的多样性结果。