
论文链接:https://arxiv.org/pdf/2211.05344.pdf
模型链接:https://github.com/ymcui/LERT
TL;DR
本文在训练PLM模型时,融入了POS、NER、DEP等基础语言学弱监督特征数据,与MLM任务共同完成多任务学习,在中文NLU数据集中取得了不错的效果。
Abstract
大多数预训练模型都是在文本的表面形式上进行语言不可知的预训练任务,如掩码语言模型(MLM)。为了进一步赋予预训练模型更丰富的语言特征,在本文中,作者提出一种简单有效的方法来为预训练模型学习语言特征–LERT。它使用语言学信息预训练(LIP)策略,根据三种类型的语言特征以及原始MLM预训练任务完成训练。在10种中文NLU任务上进行实验,带来了不错的提升。此外,本文还进行了各种语言学方面的分析实验,结果证明了LERT的设计是有效的。
1.Introduction
MLM任务由于是随机选择的Mask字符,并没有显示使用语言学特征,因此它是一个非语言学的预训练任务。之前在预训练模型中融入语言学知识的工作大多数只专注于在PLM中包含几个语言特征,而没有仔细分析单个特征对整体性能的贡献以及不同任务之间的关系。此外,因为结构知识不能直接应用到PLM中,代码实现都相对复杂。
为了缓解上述问题,在本文中,作者利用传统的NLP任务显式地包含更多的语言知识,为模型预训练创建弱监督数据。同时提出了LERT(Linguistically-motivated bidirectional Encoder Representation from Transformer),LERT使用了多任务训练的模式,包含词性标注(POS),命名实体识别(NER),依存句法分析(DEP)等任务。为了平衡每个预训练任务的学习速度,作者提出了一种LIP(linguistically-informed
pre-training)策略,该策略能够更快地学习基础语言知识。
2.Related Work
- LIMIT-BERT: 使用了5个语言学任务:词性标注,成分与依赖解析,片段,依存语义角色标注。
- LEBERT:将额外知识注入到BERT各层中,用于解决中文序列标注任务。
- CK-BERT:使用语言感知的MLM任务与对比多跳关系模型用来做预训练。
3 LERT
3.1 Overview

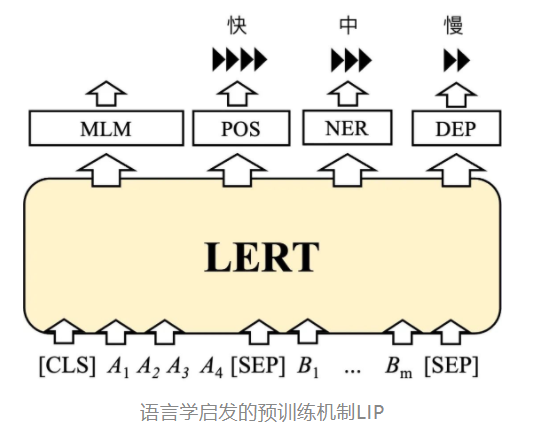
首先,对于给定的输入,进行分词提取语言特征。分词特征用于WWM与N-gram预训练任务,语言特征用于语言预训练任务,MLM任务与语言任务 共同进行训练。
3.2 Linguistic Features
本文使用LTP完成POS、NER、DEP三种语言基础特征的抽取。
- POS有28种词性类型。
- NER利用BIEOS标注模式,有13中类型。
- DEP对输入句子使用依存句法分析,对从属关系的字符进行打标,共有14种类型。
3.3 Model Pre-training
LERT在MLM与3种语言学特征上共同完成多任务预训练。
3.3.1 MLM Task
与其他预训练模型使用的MLM任务一样,也是预测被Mask掉位置的字符
3.3.2 Linguistic Tasks
本文将语言学任务视为分类任务,每个字符被映射到它的POS、NER、DEP三种标签,模型最终同样使用全连接层去映射该字符的最终标签。
3.3.3 Linguistically-informed Pre-training
最终的Loss也是和大多数多任务学习一样: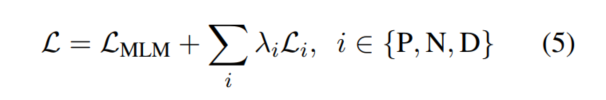
直观上来看,MLM任务肯定是最重要的任务,如何来确定每个语言学任务Loss的权重呢?
本文提出了LIP策略,仔细分析,NER特征依赖于POS,DEP特征依赖于POS与NER,因此POS特征为最基础的语言学特征,NER、DEP次之。根据它们的依赖性,本文为每个语言特征分配不同的学习速度,从而NER和DEP更快地学习POS。这与人类的学习类似,我们通常先学习基本知识,然后学习依赖的高级知识。
不同任务的权重由当前的训练步数来进行决定,具体,如下公式: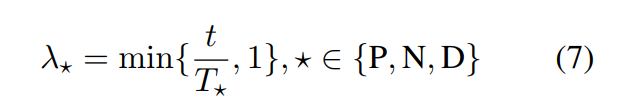
本文中,POS、NER、DEP任务的T*分别为1/6、1/3、1/2。在训练步数达到总步数一半时,各个任务的权重就相等了。因此,POS、NER、DEP任务的学习速率依次变快。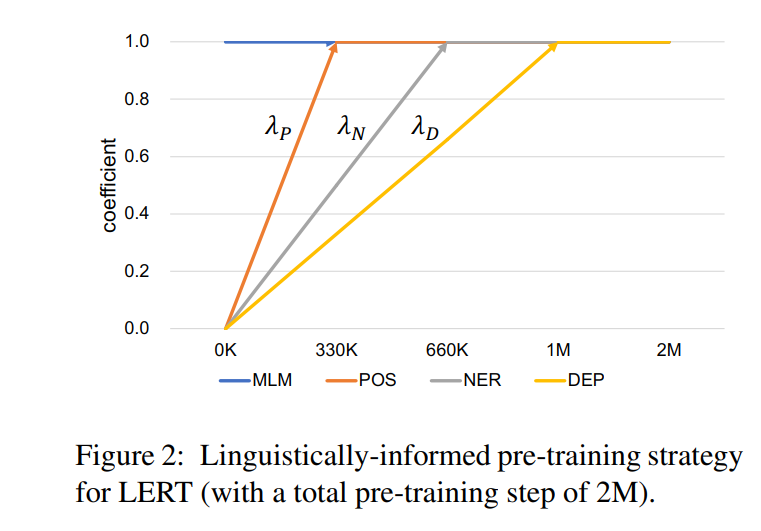
4. Experiments
具体训练模型的参数可以直接看原文。作者提供了3种不同大小的模型,LERT small、LERT base、LERT large。
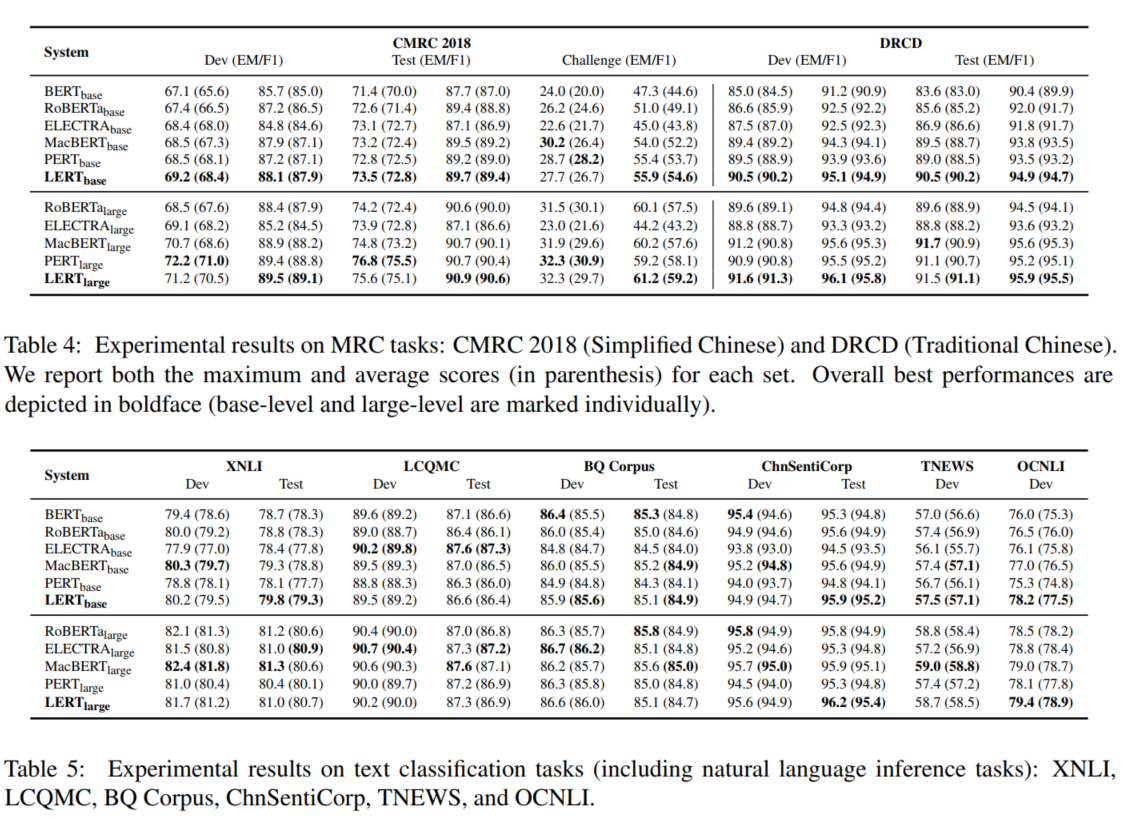
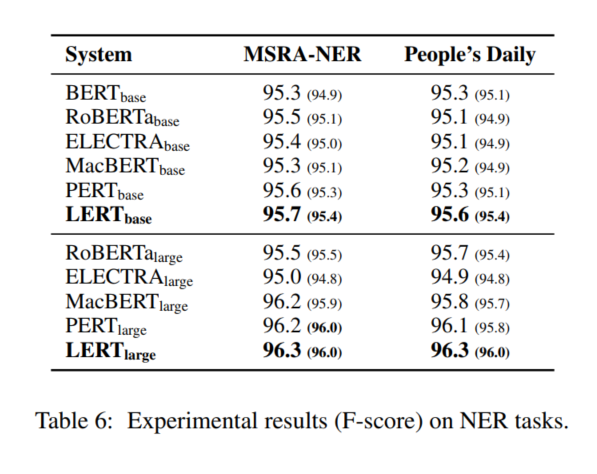
在MRC(机器阅读理解),TC(文本分类),NER(命名实体识别)任务上进行实验,下图分别为不同任务的实验结果。可以看出NER任务提升效果明显。
5. Analysis
具体的消融与分析可以直接参考原文。
6.Conclusion
本文提出的LERT使用了POS,NER,DEP等偏向学习语言特征的任务与MLM任务进行多任务联合训练。为了更好让模型获得语言知识,本文还提出了一个有效的基于语言知识的预训练策略。在多项中文NLU实验中,LERT均有了不错的提升。