论文链接:https://arxiv.org/abs/2203.06906
模型链接:https://github.com/ymcui/PERT
Abstract
本文提出了PERT,它主要用于NLU任务,且是一个基于全排列的自编码语言模型。主要思路是对输入文本的一部分进行全排列,训练目标是预测出原始字符的位置,同时也使用了WWM(全词掩码)与N-gram掩码去提升PERT的性能。在中英文数据集上进行了实验,发现部分任务有明显的提升。
1.Introduction
预训练模型通常有两种训练模式:以BERT为代表的自编码方式和以GPT为代表的自回归方式。基于MLM任务,有不少的改进方式,比如WWM,N-gram等,因此也诞生了ERNIE、RoBERTa、ALBERT、ELECTRA、MacBERT等模型。
本文探索了非MLM相关的预训练任务,动机很有趣,很多谚语篡改几个汉字不会影响你的阅读。如图1所示,打乱几个字的顺序,并不会改变人们对句子的理解。基于此想法,本文提出了一个新的预训练任务,permuted language model (PerLM),PerLM试图从无序的句子中恢复字符的顺序,其目的是预测原始字符的位置。
2.Related Work
相关工作直接贴个原文表格吧,各种预训练模型的特点表格已基本说明。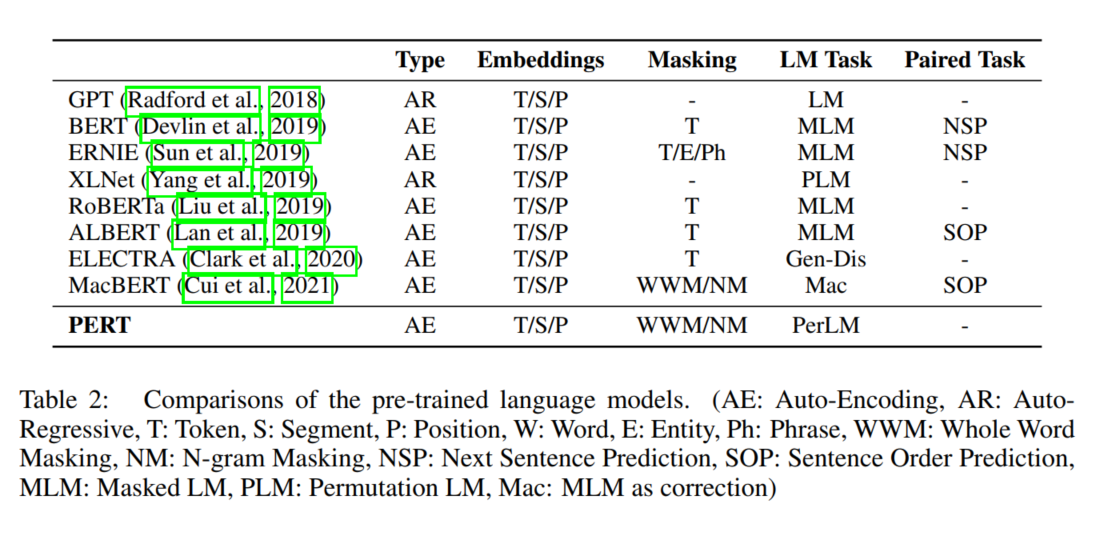
3.PERT
3.1 Overview
PERT的输入为乱序的句子,训练目标是预测原始字符的位置。
- PERT采用了和BERT一样的切词WordPiece、词表等。
- PERT没有[MASK]字符。
- 预测的空间是基于输入的句子的,而不是整个词表空间。
- 由于PERT的主体与BERT相同,通过适当的微调,BERT可以直接被PERT取代。
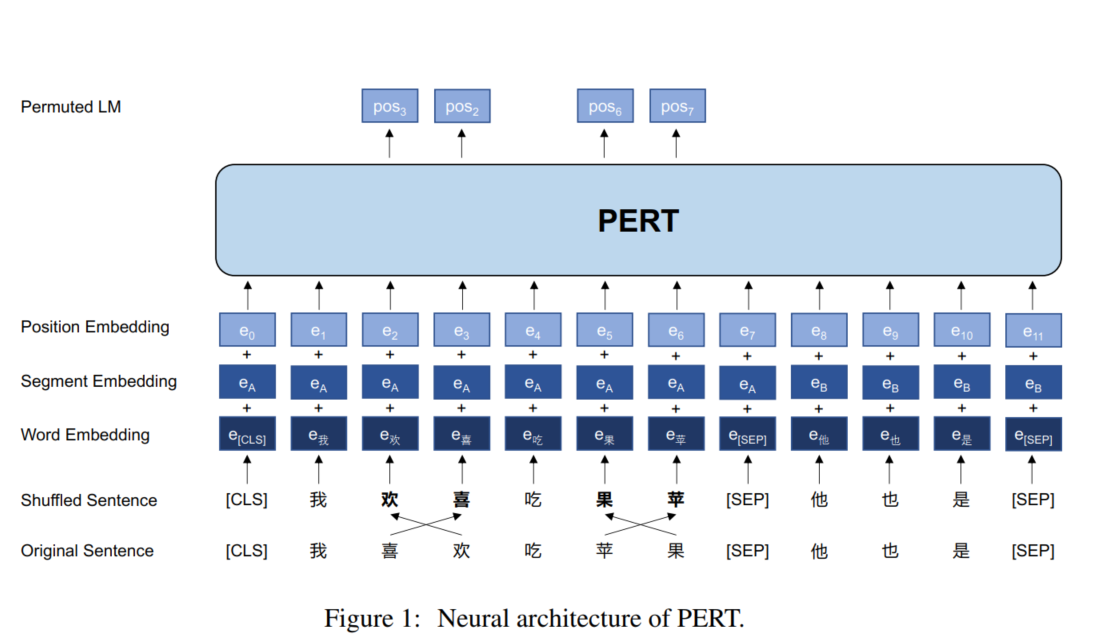
3.2 PERMUTED LANGUAGE MODEL
本文没有使用NSP任务,仅用了PerLM任务。
- 本文使用了WWM与N-gram Mask进行候选词Mask的选择,分别有40%、30%、20%、10%的概率完成单字Mask到4-gram的Mask
- 在前面的工作之后,本文使用了15%的输入词来进行Mask。
其中,- 本文随机选择90%的字符并打乱它们的顺序。
- 对于其余10%的字符,保持不变,将其视为负样本。
PerLM与MLM相比的特性如下:
- PerLM没有使用[MASK]字符,缓解了预训练-微调之间的偏差问题。
- 相比MLM任务,PerLM预测空间是句子,而不是整个词表,比MLM任务效率更高。
3.3 PRE-TRAINING STAGE
给定句子A和句子B,完成随机字符打乱之后,拼接在一起输入到PERT中。
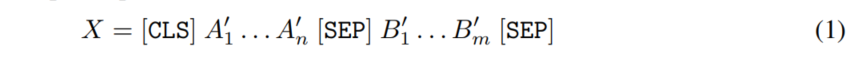
经过Embedding层与L层的Transformer结构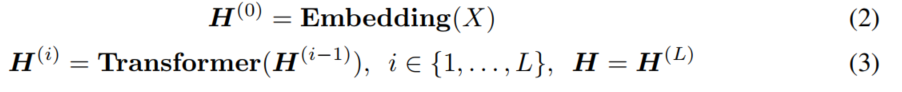
PERT只需要去预测所选定的位置,最后经过一个FFN与LayerNorm,使用softmax输出标准化之后的概率分布,损失函数为交叉熵。
3.4 FINE-TUNING STAGE
微调阶段PERT与BERT相似,可以进行直接替换,当然,微调阶段是不需要打乱句子的顺序的,直接输入原始句子就可以。
4 EXPERIMENTS ON CHINESE TASKS
具体训练参数,可以参考原论文。
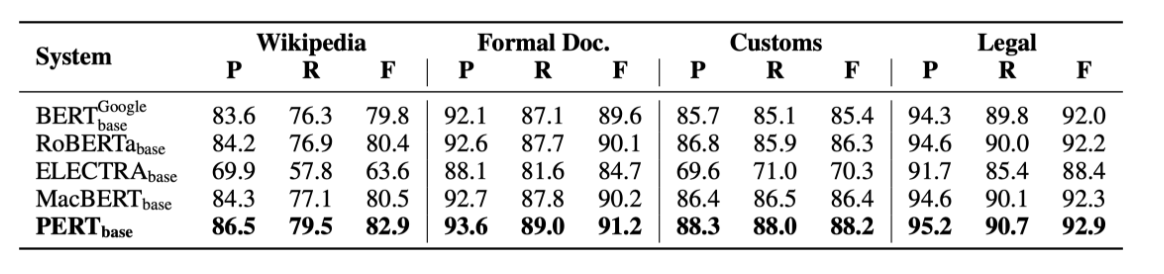
本文PERT在阅读理解MRC,文本分类TC,命名实体识别NER等任务中进行了实验。
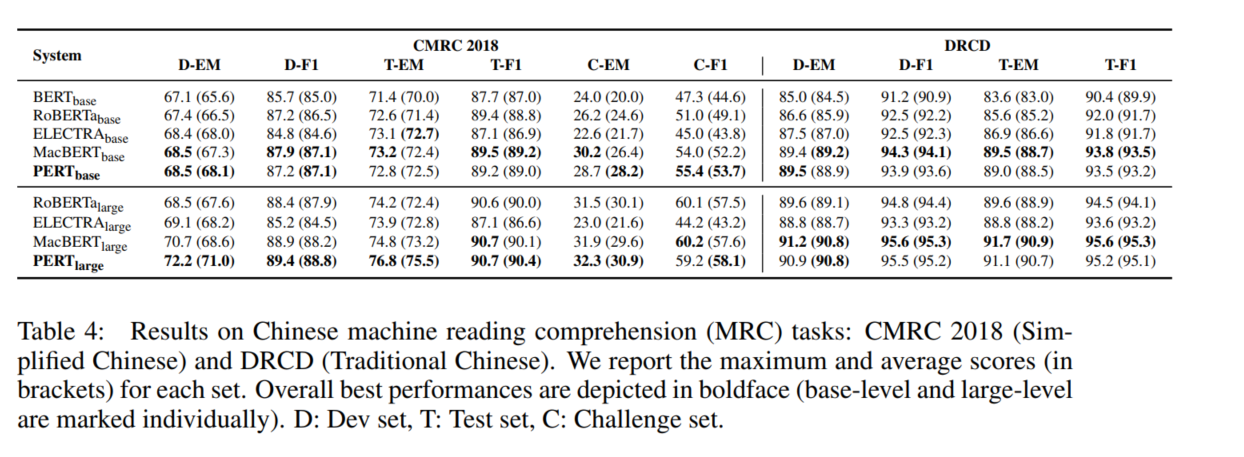


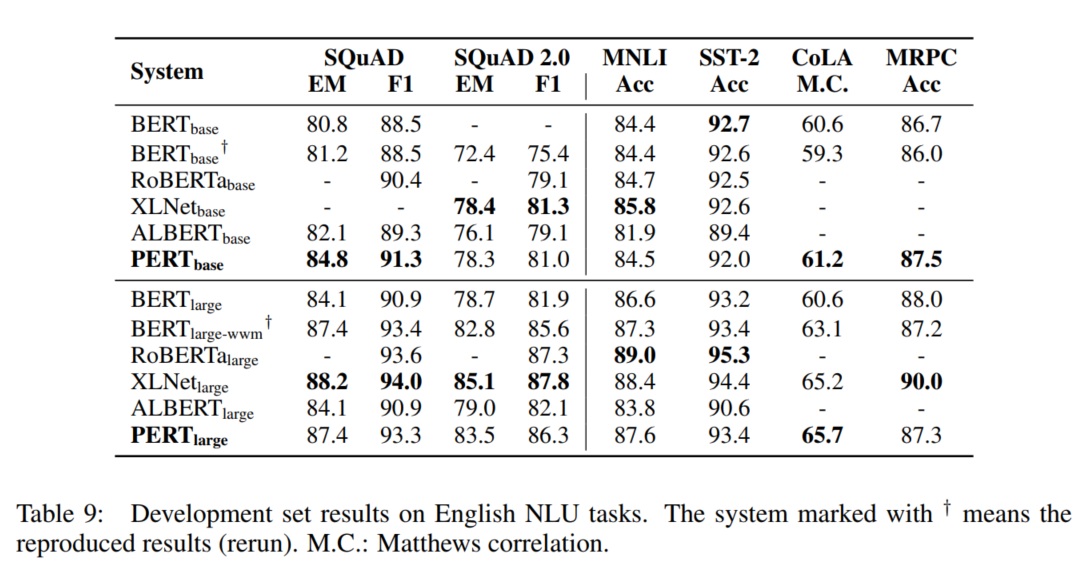
在MRC与NER任务上,PERT表现还是不错的,即使在英文数据集上也是如此。
7.Conclusion
与MLM训练任务不同,本文提出的PERT训练目标是预测被打乱字符的原始位置。该模型在MRC于NER相关任务上有了不错的提升,但是文本分类没有明显提升。
最后值得一提的是,PERT在文本纠错与乱序任务上表现不错,当然这也和它预训练-微调任务一致性有很大的关系。前段时间科大讯飞比赛的一个题目,仅用PERT就比BERT、RoBERTa等模型性能要高不少。