
论文链接
Abstract
商品显示与搜索查询意图不匹配的商品会降低电商中的用户体验。这些不匹配源于排名算法对嘈杂的行为信号(如搜索日志中的点击和购买)的不真实偏差。解决这类问题需要一个海量的标注数据,然而成本很高。本文中,我们开发了一个端到端模型,该模型学习如何有效地对不匹配进行分类,并生成难不匹配样本以改进分类器。我们通过在交叉熵损失中引入一个潜在变量来对模型进行端到端的训练,交叉熵损失在使用真实样本和生成样本之间交替进行。这不仅使分类器更加健壮,还提高了整体排名性能。
1 Introduction
基于文本的电商搜索挑战很大,可能简单的修改query,就会明显改变搜索意图。此外,用户行为的噪声也会给排序算法带来较大的误导,可能用户搜索XX手机充电器,最后购买了手机。
在本文中,我们考虑的问题主要是query-item不匹配,以提高产品搜索的排名性能。此类任务需要大量的正负样本标注数据,即使我们能够部分地负担昂贵且耗时的标记数据,所获取的数据集也是不平衡的,并且缺乏难正样本,这使得分类器无法学习稳健的决策边界。然而,上面的Iphone X和Iphone X充电器示例表明,利用标记的数据可以人工生成有意义的正样本。事实上,我们可以通过观察相应query通常购买哪些商品来启发式地构造大量负样本。问题是,我们能用这样的负样本来生成难以分类的来增强分类器的稳健性吗?我们在图1中说明了生成的目标。
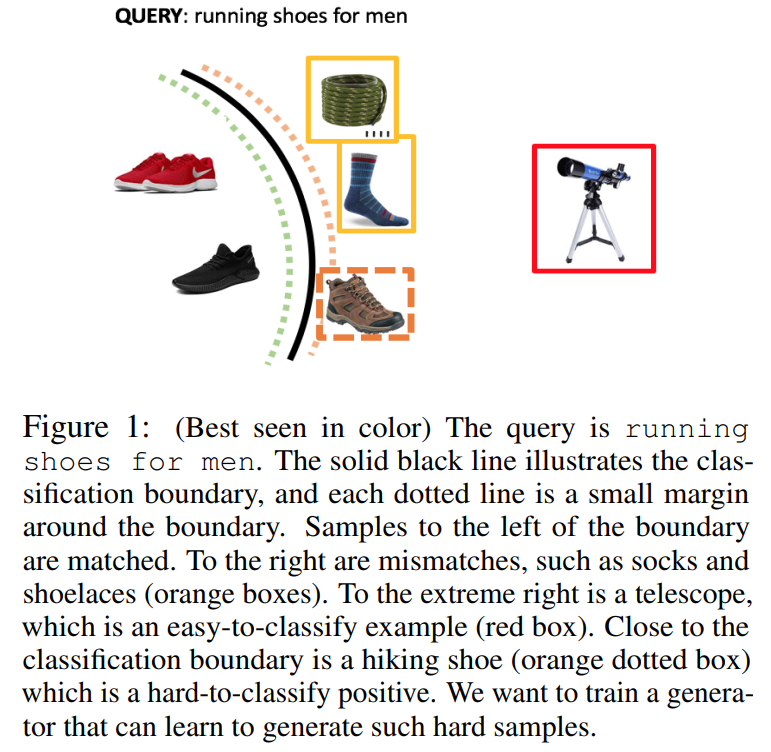
为此,我们开发了一个端到端模型,该模型能够识别不匹配的query-item对,并且能够生成给定item的不匹配query。我们在一个端到端的模型中包含了我们的分类器和生成器。分类器只需要将生成query的连续表示作为第二个输入,而不是离散的文本序列。这一关键特性使我们能够使用高效的基于梯度的优化技术,绕过基于强化学习的方法(这些方法要复杂得多),以及最近开发的启发式方法GAN等。
2 Proposed Model: QUARTS
提出模型QUARTS
(QUery-based Adversarial learning for Robust Textual Search)包含:
- 一个LSTM&Attention分类器
- 一个VED(variational encoder-decoder
query generator) 用于输出(I,Q) ,输出Q’,Q’与I不相关但是与Q 词粒度相关 - 一个状态组合器
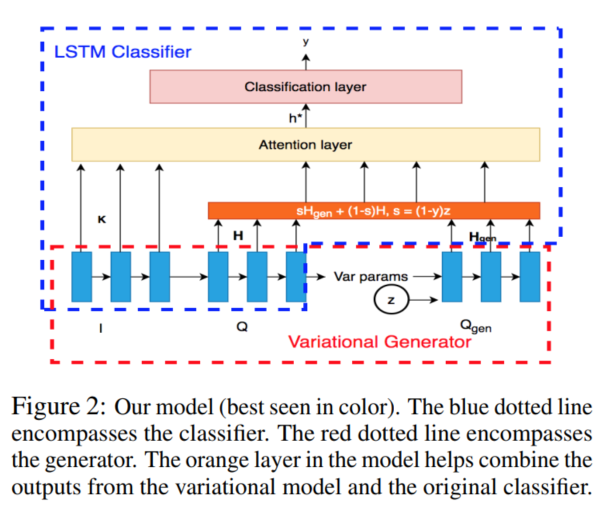
为了建立端到端的模型,我们将分类器和生成器计算的query表示结合起来,形成对注意层的适当输入。在上图橘色部分,我们增加了一个融合层,H、Hgen为相应LSTM对Q和Qgen输入的标识,z服从伯努利分布,控制Q或者Qgen是否使用。当z=0时,QUARTS计算不匹配的概率。
- y=0—>s=z ,这样就可以同时输入H和Hgen
- y=1—>s=0,仅输入H
具体训练过程如下:
3 Experiments and Results
实验不多说了,具体有兴趣看原文。
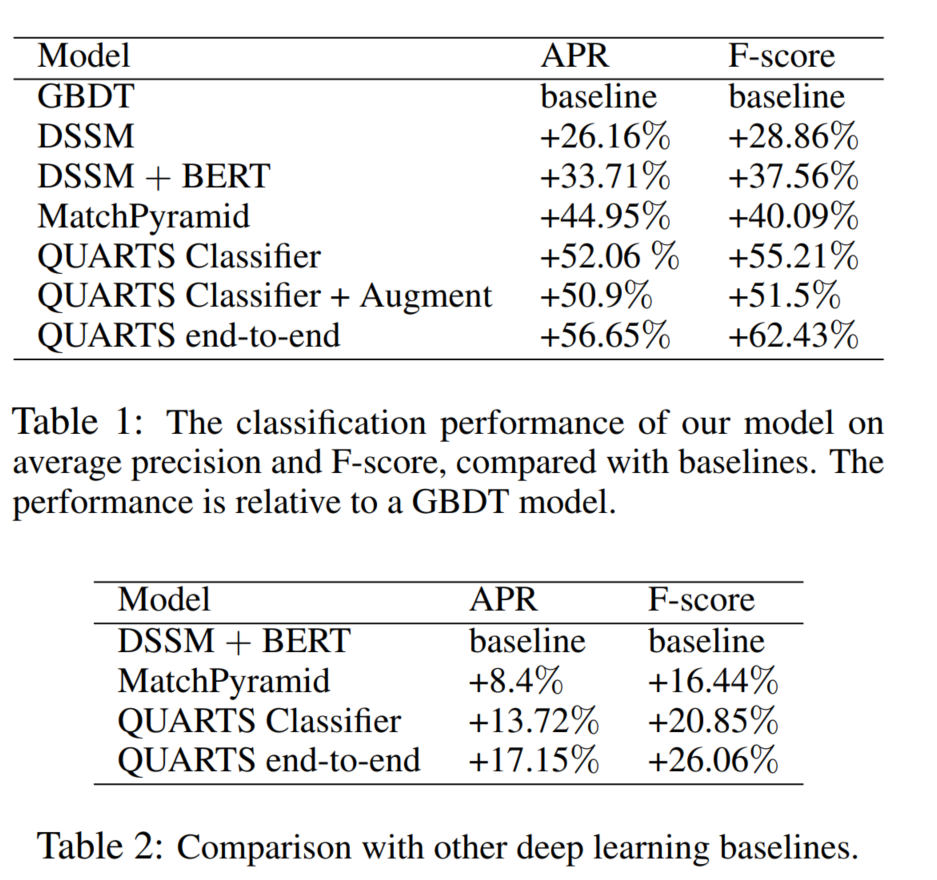
4 Conclusion and Future Work
我们开发了一个端到端的模型,用于在电商产品搜索中检索难以分类的query。我们基于文本蕴涵的思想,使用逐字attention层帮助创建以输入query为条件的表示。我们训练了一个生成器,它生成与源项不匹配的query表示,同时又是“真实的”。这允许我们解决数据集的类别不平衡问题,同时生成有助于稳健训练分类器的样本。为了对模型进行端到端的训练,我们修改了交叉熵损失,从而避免了优化极小极大目标。在离线数据集和实时产品搜索流量上的实验表明,我们的方法比基线显著提高。