
搜索系统的评价维度一般包括性能评价和效益评价。性能评价一般包括时间性能和空间性能。系统响应的时间越短,占用的存储空间越小,系统的性能就越好。但时间优越性和空间优越性一般不能兼得,需要取舍。对于搜索系统而言,我们除了考虑响应时间和存储空间之外,还需要考虑其他重要指标,如排序相关性等,即需要考虑检索结果列表的全面性、准确性等效果指标。效益评价主要用来测量搜索系统的服务或者系统本身投入使用时所获得的收益,包括经济效益和社会效益。但效益评价一般很难量化,因为其具有滞后性和不确定性。
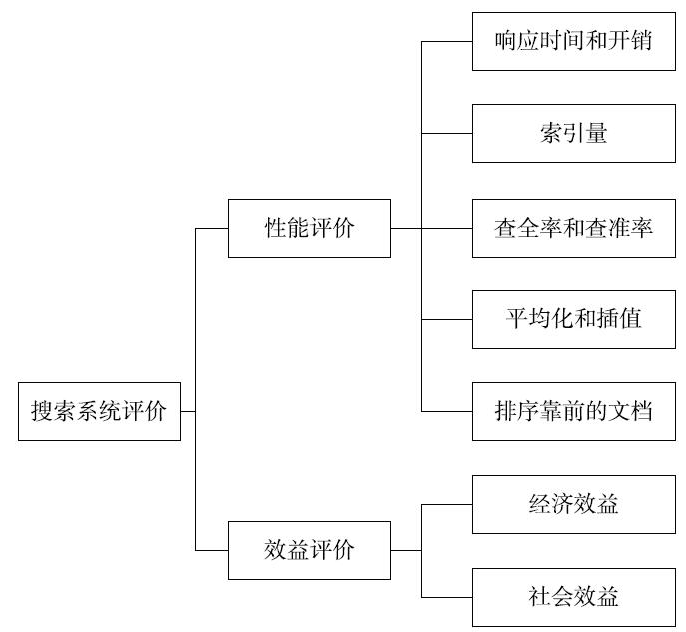
1.搜索系统的评价体系
1.1 效率评价
效率评价是对性能评价中时间性能和空间性能的概括。响应时间、开销和索引量属于时间性能和空间性能的范畴,是需要重点评测的方面。
1.响应时间和开销
对于任何一个应用系统,响应时间是评价系统的重要指标。搜索系统的响应时间分为两种情形:委托检索和非委托检索。委托检索表示用户送交查询给专业检索人员,由专业人员操作搜索系统进行检索,然后将检索结果返回给用户。非委托检索表示用户自行操作检索系统得到结果。随着网络的快速发展,多数用户采用的是非委托检索。另外,计算响应时间一般是针对某一个查询而言,但查询的长短、复杂度是不同的,所以对应的响应时间也是不同的。
除去网络拥挤、通信等外部因素的影响,影响响应时间的因素如下。
1)文档库规模。文档库规模越大,检索时间越长,响应时间也就越长。
2)硬件因素。机器配置越高,运行速度越快,响应时间也就越短。
3)检索软件。检索软件性能越好,检索时间越短,响应时间也就越短。
4)存储设备类型和数据的存储结构。存储设备的访问速度越快,数据的存储结构越合理,检索越容易,响应时间也就越短。在实际应用中,响应时间的估算不可避免地受到网络和工具性能的影响,造成同一检索在不同时间、不同地点、不同检索系统中,响应时间不同,因此有必要在不同时间段、地点等不同环境下多次计算。
存储空间的开销主要是指系统所占用的内存空间和外存空间。当检索系统内存空间有限时需要合理分配,一般情况采用中型计算机,不存在内存不足的问题。不同的文档结构所需的外存空间区别较大,比如正排索引和倒排索引所需的外存空间不同;同样是倒排索引,系统选择布尔检索还是全文检索,所需的外存空间也不同。
2.索引量
所谓“索引量”,就是搜索引擎抓取到页面后,经过分析筛选可以被用户搜索到的页面的数量。所以索引量越大,搜索引擎的数据覆盖范围越广。索引量经常和收录量混淆,收录量是搜索引擎抓取过、分析过的页面。所以从定义看,收录在索引之前,即页面没有被收录就不可能被索引。以百度搜索引擎为例,提高网站索引量的方法如下。
1)提高网站内容的质量,爬虫喜欢原创的文字性内容。
2)设置合理的内链,确保爬虫可以顺利爬行。爬虫通过内链爬向网站的各个部分,所以内链越强大,爬虫爬行越顺利,可以给网址排名和收录加分。
3)建设高质量的外部链接,因为网页的权重和外部链接的内容质量相关。
4)网站首页保持更新,以便搜索引擎认为该网站是活跃的。
5)网站不要轻易更换域名。域名更换会导致搜索引擎对网站的信用度和友好度下降,也会影响搜索引擎对网站的收录量。
在知道了索引量的定义之后,我们再来看看如何设定合适的索引量。由于索引量是一个与工程息息相关的概念,这里我们先要厘清索引的使用和存储。
以常见的Lucene系统举例,Lucene系统中索引其实是对固定分析字段拆解的倒排索引结果。索引的内容主要与拆解后的词、词在文本中的位置、文本的标号相关。而实战中,通常注重当前使用的搜索引擎的耗时和稳定性。所以,我们会考虑给一个庞大的搜索集群配备主集群、备份集群以及备用集群等。在不考虑索引量对磁盘空间占用的情况下,索引量其实与搜索集群的性能息息相关。来自搜索集群外部的搜索请求的大致流程如下。
1)请求到达主节点,主节点对请求进行分析重构,分发给子节点。
2)子节点遍历底层的索引,将所有与结果相关的数据返回给主节点。
3)主节点综合处理所有子节点的返回数据,并返给搜索集群外部。
那么在衡量一个搜索引擎的耗时时,我们可从以下4方面考虑:搜索集群外部与搜索引擎通信消耗的时间、主节点处理消耗的时间、主节点与子节点通信消耗的时间、子节点搜索索引消耗的时间。同等情况下,索引量越大,搜索耗时就越长。同时,更大的索引量对于服务器I/O性能的要求也更高,所以如何选择索引量的大小,需具体情况具体分析。
1.2 效果评价
本节的效果评价主要包含:准确率和召回率、平均化和插值以及排序靠前文档的质量。
1.准确率和召回率
准确率和召回率是搜索引擎在效果评价中最常用,也是公众最认可的指标。准确率又叫查准率(Precision Ratio,P),用来衡量检索结果中有多少文献与查询相关;召回率又叫查全率(Recall Ratio,R),用来衡量一次检索中与查询相关的文献有多少被检索出。准确率和召回率的计算如式(6-1)和(6-2)所示。

利用数学语言分析准确率和召回率:假设某搜索系统的数据库中所有文献的总量是L,对于某个查询,a表示被检索出的与查询相关的文献数量;b表示被检索出的与查询无关的文献数量;c表示与查询相关,但是没有被检索出的文献数量,则:
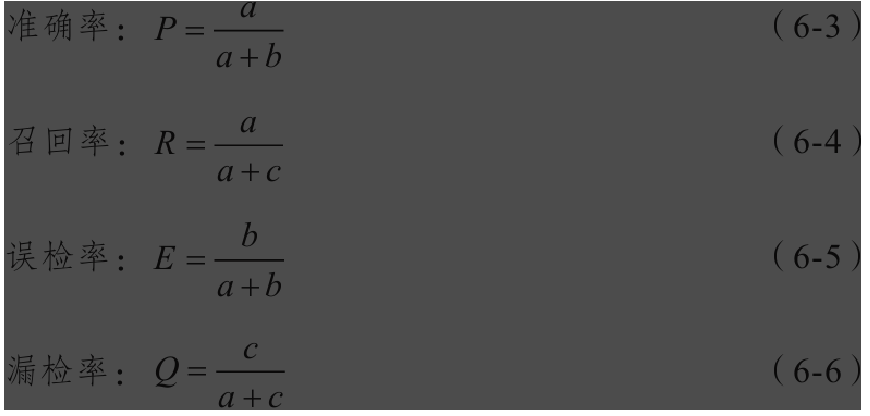
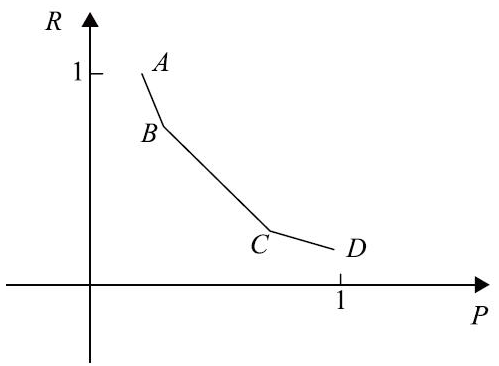
准确率和召回率之间存在什么关系呢?一个理想的搜索系统,应该是P=1、R=1,但实际上不存在这样的搜索系统。一般来说,准确率和召回率之间存在着反变关系,即如果提高准确率,召回率往往就会下降;如果提高召回率,准确率就会下降。两者相互制约。准确率和召回率的关系如下图所示,A点召回率很高,但是准确率很低;D点和A点相反,准确率很高,召回率很低;B、C两点是上述两种情况的折中。
影响搜索系统准确率和召回率的主要因素如下。
1)文档库的质量。文档库的文档是否齐全、索引体系是否完善、检索途径的多少都会影响准确率和召回率。
2)对检索需求的理解。要想达到较高的召回率和准确率,就应该较好地理解需求,制定相应的检索策略。
3)检索语言的一致性。检索的实质是比较查询和数据库文档的一致性,所以需要不同检索人员表达检索主题的语言和数据库文档一致,更需要标识查询和标识文档的语言一致,这样才能够确保检索的准确率和召回率。
4)标引的网罗性。对数据库文档主题分析得越透彻,抽出的关键词就越多,检索时能够检出的相关文献就越多,召回率就越高,但准确率就会降低;反之,如果标引是只标注中心主题,检出的文档的准确率就会比较高,但是漏检会增多,召回率会降低。
5)检索词的专指性。检索词的词意越狭窄、越具体、越专深,检出的文档就会越对口,准确率就会越高,但命中的文档数量就越少,召回率会降低;反之,如果检索词越笼统、越宽泛,检出的文档数量就会增多,召回率就会升高,但检出的文档不相关的可能性也会增加,准确率会下降。
一个优质的搜索系统应该具备高的准确率和召回率,但并不是每个用户在任何时候都需要高准确率和召回率。用户需求可以分为以下4种情况。
1)要求召回率R=1。例如申请专利、发明等,需要对全世界范围的有关文档全面了解,才能做出客观的评价,这时就需要R=1的搜索系统。
2)要求较高的召回率。例如编写教材、某技术的发展综述,往往需要较全面地获得有关文档,这时对召回率要求较高,但不一定要求R=1。
3)要求较高的准确率。例如要了解某种产品的有关信息,解决某一具体问题,往往只需要了解某一个方面或者相关信息,这时对准确率要求较高。
4)对准确率、召回率没有具体的要求。对于某些检索,用户本身不能够做出明确的表达,因此,对准确率和召回率也无法提出确切的要求。
如何综合评价准确率和召回率呢?一般使用F值度量(F-measure)综合衡量准确率和召回率。它的好处在于能够使用单一的数字综合反映系统性能,被定义为准确率和召回率的调和平均数,如公式(6-7)所示。使用调和平均数而不是数字平均数的原因是,调和平均数强调较小的值的重要性,数字平均数受极值影响较大。假设一个查询的召回率为1,准确率为0,数字平均数是0.5,但调和平均数为0,更好地评价了搜索结果。

一个查询会返回很多结果,但一般用户关注的数量是有限的,所以在计算准确率和召回率的时候不能按照所有的返回结果去统计,而是可以简单地在一些预定义的位置上计算准确率、召回率来评估此次搜索结果,这种评估方式被称作位置p的准确率(Precision at Rank p)。由于用户比较关心排序靠前文档的数量,最常使用的是p@10或者p@20。第二种评价方法是,当召回率每增加0.1时,计算准确率的变化。这种方式能够评价排序结果中所有相关的文档,不只是排序靠前的文档。第三种评价方法是,计算一个额外的相关文档被检出时,平均准确率的变化情况。这种方法能够衡量所有相关文档的排序结果,同时严格依赖于排序位置靠前的相关文档。
2.平均化和插值
以上描述的评价方法都是针对一次查询结果进行评估的,要想更加客观准确地评价检索算法的优劣,必须使用多个查询结果进行测试。本节将讨论对查询集合进行评估的方法——平均化和插值法。
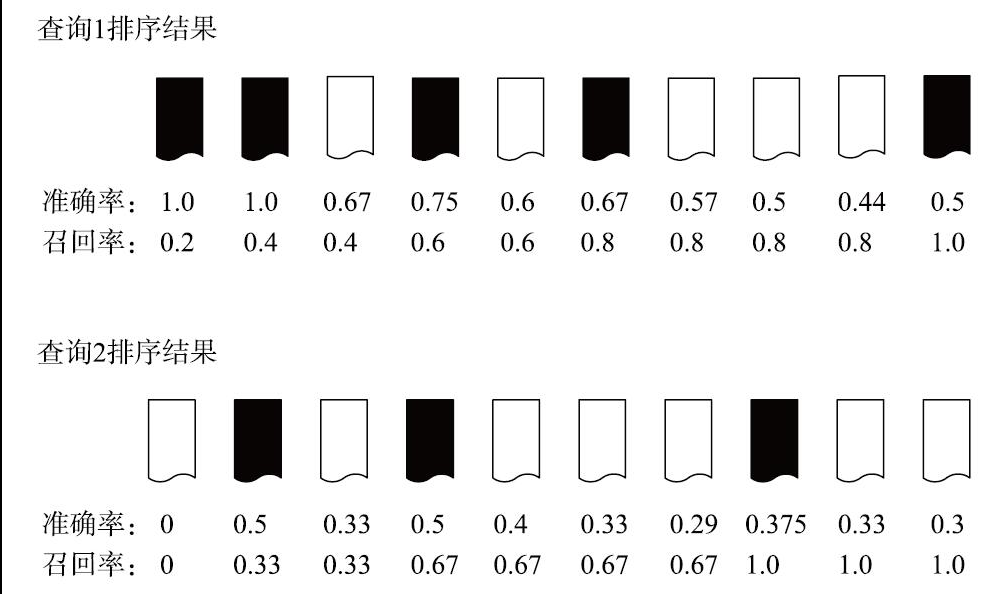
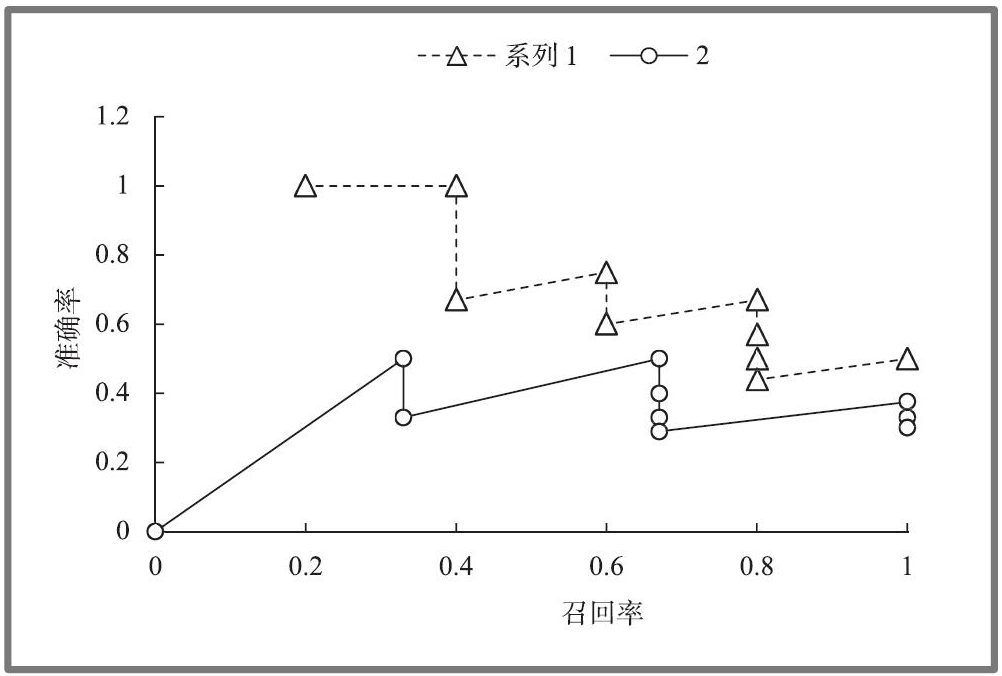
平均准确率(Mean Average Precision,MAP)是综合多个查询结果进行评价的最简单的方法,就是对多次查询结果求平均,这也意味着它假设每个用户都期望找到更多相关的文档。MAP计算方法示例如下图所示,黑色表示查询的相关文档,白色表示查询的不相关文档,查询1的平均准确率=(1.0+1.0+0.67+0.75+0.6)/5=0.804,查询2的平均准确率=(0+0.5+0.33+0.5+0.4)/5≈0.35。MAP=(0.804+0.35)/2=0.577。
MAP评价方法简单,便于计算且有效,能够给出详细的搜索算法的性能,但会丢失很多文档信息。下图为两次查询的准确率–召回率图,其中系列1对应查询1,系列2对应查询2。每个查询对应的准确率–召回率曲线差异较大,不便于比较。为了生成一个能够综合反映查询结果的准确率–召回率图,我们对准确率–召回率的值进行平均化。该平均化的过程是将每次查询的准确率–召回率值转化为标准召回率等级对应的准确率。
标准召回率的等级在0到1之间,增量是0.1。为了获取每个增量上的准确率,我们对上图的准确率–召回率数据进行插值,使每个召回率的增量等级上都有数值。在搜索评价体系中,插值法定义在任何标准召回率等级R处的准确率P为:

3.排序靠前文档的质量
在很多搜索系统中,用户更关注排序靠前的相关文档。我们日常浏览页面时,可能不会往后翻很多页,注意力主要集中在第一页或者前两页。对于一些问答类查询,用户更倾向于直接获得一个明确的结果,这种情况下使用召回率并不合适。因此,关注搜索引擎排序结果中靠前文档的质量,在评价搜索结果的时候至关重要。
前文已经讲过计算位置p的准确率,其中p的取值一般是10或者20。这种方法通过多次评价查询结果的质量,然后给出结论,计算简单。但是,其也存在一些问题,即没有对相关文档的顺序做详细区分,因此需要关注文档排列的顺序。
MRR(Mean Reciprocal Rank)是指多个查询的排名的均值,是国际上通用的对搜索结果进行评价的指标。假设有两次查询,第一次查询的第一个相关文档的排序是2,第二次查询的第一个相关文档的排序是5,那个根据这两次查询对搜索结果进行评价,计算方法是:1/2(1/2+1/5)=0.35。MRR方法主要应用于寻址类检索或者问答类检索。MRR的计算如式(6-9)所示。

对于网络搜索评价来说,DCG(Normalized Discounted Cumulative Gain)是较为常用的方法。这种方法基于两个假设:1)高相关性的文档比边缘相关的文档更重要;2)一个相关文档的排序越靠后,对用户的价值就越低,因为它们很少被用户查看。这两个假设产生了一种新的评价方法——相关性设定等级,其作为衡量文档增益的标准。这种增益是从排序靠前的结果开始计算,但靠后的排序位置上的增益会有折扣。DCG方法就是在一个特定的位置p的前提下,计算文档总的增益。在介绍DCG之前,先描述一下CG(Cumulative Gain),其表示前p个位置累计得到的增益,公式如(6-10)所示。


还有一种比较常用的计算方式——增加相关度影响比重,如公式(6-12)所示。


