
1.搜索和机器学习
搜索引擎包含两个阶段:召回和排序。搜索系统中所涉及的机器学习的算法会分布在两个部分。第一部分是对Query及文档的理解过程,因为理解过程中使用了自然语言处理等相关算法。第二部分就是排序学习过程,即将机器学习技术应用到排序阶段,
1.1排序学习
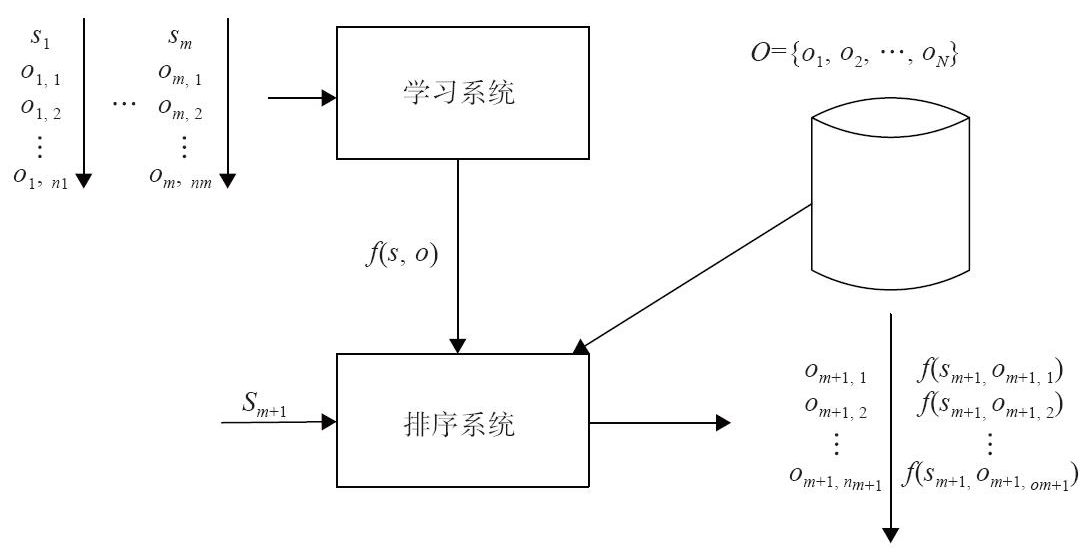
传统的检索模型靠人工来拟合排序公式,并通过不断地实验确定最佳的参数组合,以此构成相关性打分函数。机器学习排序与传统的检索模型不同,可通过机器学习获得最合理的排序公式,而人只需要给机器学习提供训练数据,如下图所示。

机器学习排序由4个步骤组成:人工标注训练数据、文档特征抽取、学习分类函数、在实际搜索系统中采用机器学习模型。机器学习排序框架如下图所示。
单文档方法(Pointwise):处理对象是单一文档,将文档转化为特征向量后,将排序问题转化为机器学习中常规的分类或回归问题。CTR方法是单文档方法的典型应用,相对比较成熟,广泛应用于广告、搜索、推荐中。CTR方法的数学表达式:y=f(x),其中y的范围为[0,1],y的值越大表示用户点击率越高。
文档对方法(Pairwise):相比于单文档方法算法,文档对方法将重点转向文档顺序关系,是目前相对比较流行的方法。其输入是文档对,输出是局部的优先顺序,主要是将排序问题归结为二元分类问题。这时,机器学习方法就比较多,比如Boost、SVM、神经网络等。对于同一Query的相关文档集中,任何两个不同标记的文档都可以得到一个训练实例(di,dj),如果di>dj,则赋值+1,反之为-1。于是,我们就得到了二元分类器所需的训练样本。预测时可以得到所有文档的一个偏序关系,从而实现排序。

文档列表方法(Listwise):与上述两种方法不同,其将每个查询对应的所有搜索结果列表作为一个训练样例。根据训练样例训练得到最优评分函数F,评分函数F对每个文档打分,然后根据得分由高到低排序,得到最终的排序结果。这种方法的输入是文档集合,输出是排好顺序的列表。文档列表方法排序示意图如下图所示。
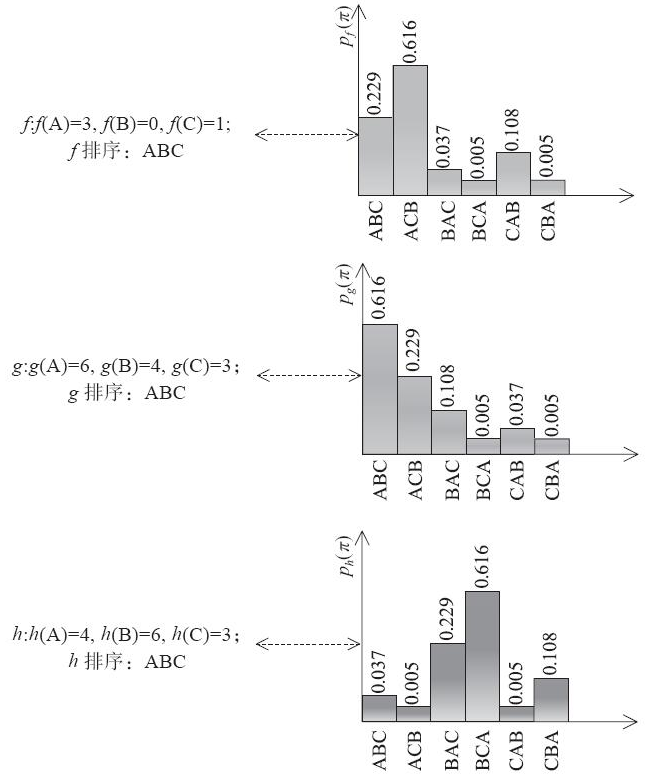
三者之间的区别就在于训练数据之间的关系对预测目标的影响不同。简单地说,单文档排序算法是点点之间排序,训练数据之间的关系与最终排序无关。换句话说,样本经过模型训练形成的是一种评分方式,而所有样本按照评分结果由大到小排序即可。模型生成后,每个样本的输出结果是固定的、静态的,不会发生变化。这里典型的单文档排序算法有逻辑回归、树模型等。事实上,所有利用二分类问题归纳的排序算法都可以当作单文档排序。其根本逻辑就在于设定两个分类1、0,在训练样本时考虑每个独立样本与当前分类的关系,生成模型参数。在排序过程中,先计算每个样本当前参数耦合后的结果再总体排序即可。
而对于文档对方法,输入的是文档对。比如现在有三个文档D1、D2、D3,排序为D1>D2>D3,那么输入应该是<D1,D2>、<D2,D3>、<D3,D1>,对应的训练目标是“文档1是否应该排在文档2的前面”。这种方法在模型构造上与大部分单文档方法可以共用原始模型,好处在于模型训练出来的是对应文档组的排序关系,在复杂、高维度、不易解析的情况下,有时会比单文档方法的排序结果更接近真实值。但是其缺点也很明显,其中一个缺点是由于模型输出的两个文档之间有排序先后关系,如果靠前的位置出现错误,那么对于整体排序的影响是远远大于单文档方法。另一个缺点是模型较难对输出结果进行评价且训练困难,由于不同情况下文档之间的关系多种多样,而且不同情况下,不同的输入对训练产生的影响不同,因此很难对模型整体输出结果做出评价。同时,文档对方法一方面增加了标注的难度,另一方面增加了训练的时间。
而文档列表方法与前两者都不同,其考虑的是模型整体的排序结果,输入是一个文档列表,且每一个文档的对应位置都已经锁定。例如,输入是[D1,D2,D3],那么该方法认为单次样本的输入中,排序为D1>D2>D3。该方法的代表模型有Lamda Rank、Ada Rank等。得益于NDCG等新的评价方式,文档列表排序在模型训练的过程中可以有效地迭代数据。而且由于输入的单个样本是一组标注好的序列,模型在迭代的过程中也更容易贴近用户需求。文档列表排序方法的缺点也有很多。首先,在理想情况下,其确实更容易保证模型的排序结果贴近用户需求,但是这需要前期大量的标注工作或者说对于使用场景有着明显的限制。其次,由于独立样本复杂,模型的训练成本大于其他两种方法。最后,在现实生活中,我们往往很难能确定地输入单个样本的排序。我们还是要根据具体场景选择合适的排序方法。
1.2排序学习示例
Bagging和Boosting算法对比如下图所示。
Boosting示意图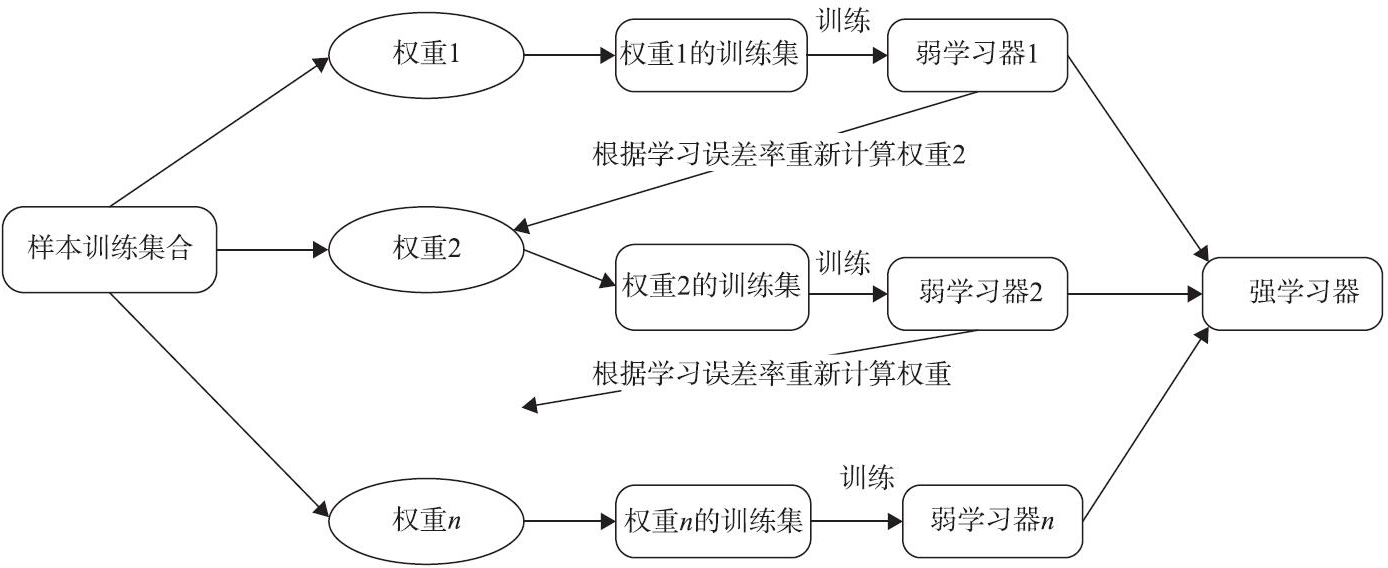
Bagging示意图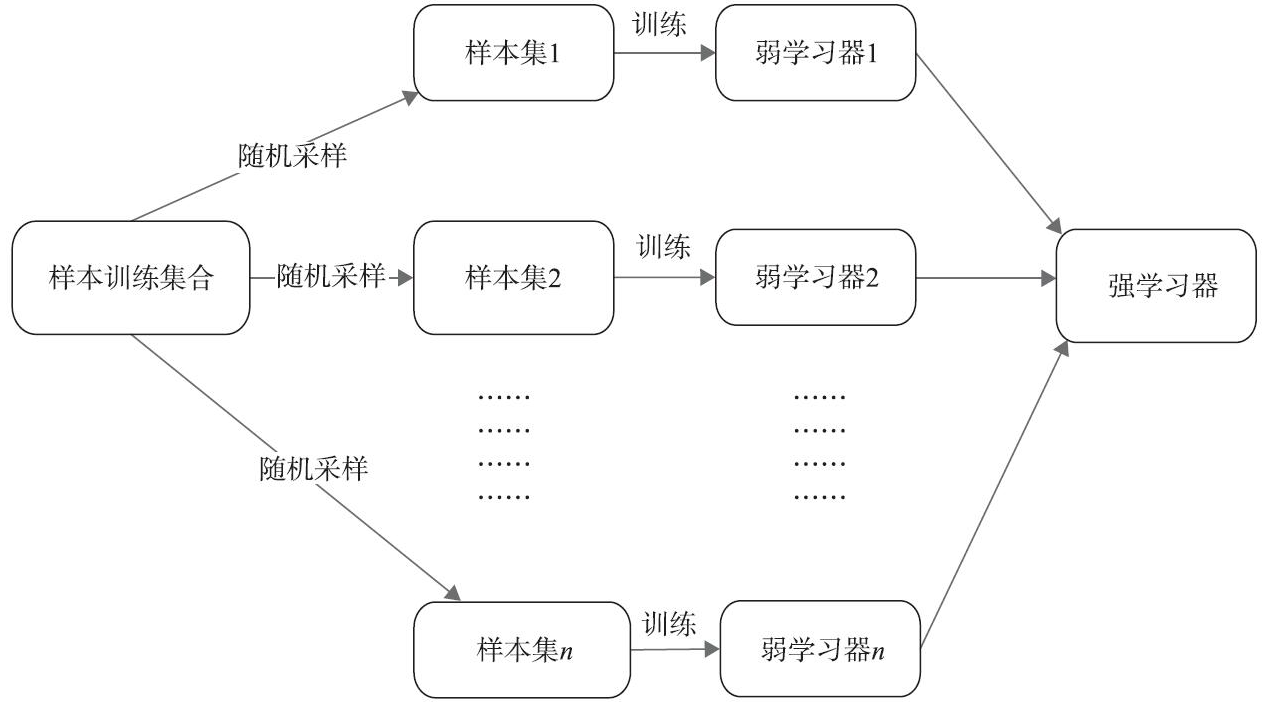
1.3搜索和深度学习
1.3.1 深度神经网络(Deep Neural Network,DNN)
DNN模型的优缺点。作为深度神经网络模型,其对于非线性问题的处理优势不言而喻,而在搜索乃至推荐系统中,由于很多时候特征与训练目标间的关系并不清晰,所以DNN模型对高维度特征的提取更是一大优势。这也是有些场景下,DNN的表现要比树模型、FM家族模型要好的原因。但是DNN本身也有不足,如对类别特征的支持不好,随着类别特征的增多,甚至可能产生维度爆炸的情况;对系统算力的要求较高,因为为了能更好地提取高维度特征,模型的深度可能会使算力不足的问题进一步加剧;可解释性较差,随着隐藏层的增多,评估不同特征对模型的影响变得尤为困难。
1.3.2 深度结构语义模型(Deep Structured Semantic Models,DSSM)
深度结构语义模型(Deep Structured Semantic Models,DSSM)在计算语义相关度方面提供了一种思路。它的思想很简单,就是将Query和Title的海量点击曝光日志用DNN(Deep Nature Networks)表达为低维语义向量,并通过余弦相似度来计算两个语义向量的距离,最终训练出语义相似度模型。DSSM模型既可以用来计算两个句子的语义相似度,又可以获得低维语义向量表达。
DSSM模型从下往上可以分为三层:输入层、表示层、匹配层,如下图所示。
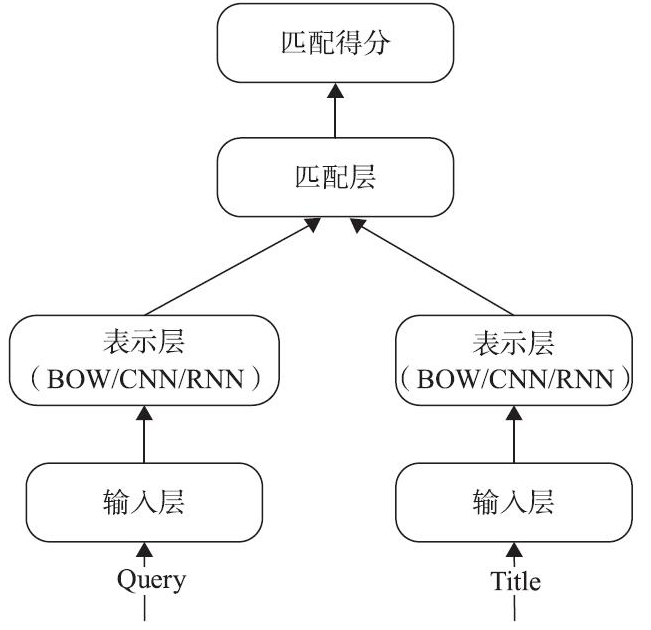
(1)输入层
输入层的作用是把一个句子映射到一个向量空间(中文可以处理为单字的形式),并输入到DNN中,然后计算Bi-gram或者Tri-gram。
(2)表示层
表示层采用BOW(Bag of Words)的方式,将整个句子的词不分先后顺序地放到一个袋子里,如下图所示。
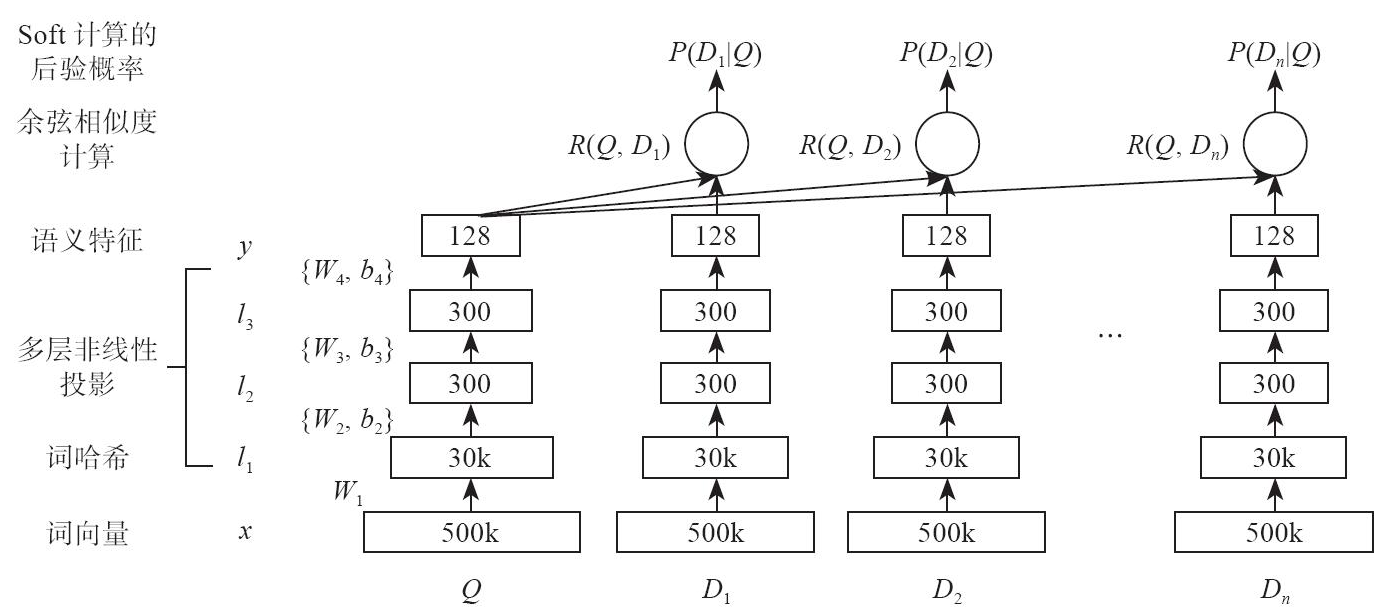
用Wi表示第i层的权值矩阵,bi表示第i层的偏差项,则第一个隐藏层向量l1(300维)、第i个隐藏层向量li(300维)、输出向量y(128维)可以分别表示为:

(3)匹配层
最后,在匹配层用三角余弦计算Query和Doc的相似度。

DSSM用字向量作为输入既可以减少对切词的依赖,又可以提高模型的范化能力,因为每个汉字所能表达的语义是可以复用的。另一方面,传统的输入层是用单词向量化的方式(如Word2Vecor的词向量)或者主题模型的方式(如LDA的主题向量)来直接做词映射,再把各个词向量累加或者拼接起来。但由于Word2Vecor和LDA都是无监督训练,会给整个模型引入误差,而DSSM采用统一的有监督训练,不需要在中间过程做无监督模型的映射,因此精准度会比较高。
DSSM的缺点是采用词袋模型(BOW),导致丧失了语序信息和上下文信息,而且采用弱监督、端到端的模型,使预测结果不可控。