
ABSTRACT
本文提出了Que2Search,用于搜索场景下query和product理解系统。Que2Search使用多模态和多任务去训练query和product的表示。通过将最新的多语言自然语言理解体系结构(如XLM和XLM-R)与多模态技术相结合,我们实现了超过5%的绝对离线相关性改进和超过4%的在线收益,超过了最先进的Facebook产品理解系统。下文也会描述基于大量离线和在线A/B实验的哪些模型优化有效(哪些无效)。
1 INTRODUCTION
传统的搜索引擎使用基于各种term匹配的算法,最近有人提出了基于embedding的检索方式,使用wide and deep网络去为query和doc构建embedding;这些方法缺乏代表性,由于计算性能问题没有引入BERT。
本文介绍了Que2Search,一种query2product相似性模型,它提供了一种考虑综合多模态特征的建模方法,并利用XLMR进行文本特征编码。Que2Search在弱监督数据集上训练,相比于之前的FB baseline,实现了SOTA;并已部署到了FB Marketplace,它增强了基于product embedding的检索的query检索能力,还可用作排名特征。
以下是几个Que2Search的挑战:
- 产品描述充满噪声。卖方提供的产品描述质量差异很大。在许多情况下,产品的属性丢失或拼写错误。
- 国际化支持。我们希望构建一个模型,在启用Facebook Marketplace的情况下,该模型能够在多种语言中运行良好。
- 有效处理多模态。我们需要将所有多模态特征(如产品图像和文本信息)有效地考虑到一个模型中。
- 严格的延迟约束。我们需要满足搜索引擎的严格延迟约束,这尤其具有挑战性,因为我们使用基于Transformer的语言模型,这在计算上非常昂贵
由于基于Transformer的语言模型参数较多,推理速度也会很慢,推理时间对于搜索问题尤其重要,因为我们需要为实时的自由文本query提供embedding表示。query侧,我们使用2层的XLM encoder去编码query,product侧,我们使用多语言XLM-R去编码商品文本描述等信息。Que2Search通过引入几种建模技术在生产应用中取得了进展,包括多阶段课程学习、多模态处理和多任务学习,这些技术可以联合优化对产品检索任务和产品分类任务的query。
2 RELATED WORK
- 基于embedding的检索方式。孪生网络、双塔模型、wide&deep等
- 多模态建模。之前大多使用双塔模型,分别编码query与doc,本文使用孪生结构
- 自然语言处理。BERTs、XLM-R
3 MODELING
3.1 Model architecture
模型结构如下图所示:
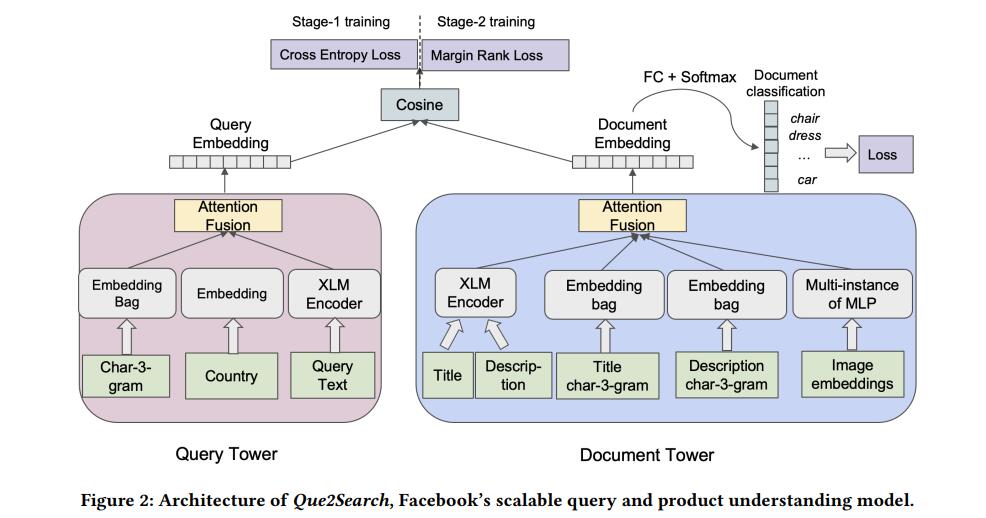
query塔:使用3个输入特征:tri-gram字符特征(多类别特征,hash滑窗等方法获取embedding之后sum_pool作为每个句子表示),搜索用户的国家(单类别特征,同样的EmbeddingBag方法),原始的query文本(2层XLM编码,提取最后一层[CLS]表示作为句子表示),最后使用attention层融合三个特征得到query的最终表示。
doc塔:输入包含product的标题、描述和图像,同样使用了EmbeddingBag编码文本的tri-gram等特征,使用预训练的MLP layer完成图像编码,最终也使用attention层去获取最后的doc表示。使用simple attention方式优于concat特征的融合方式。
具体训练细节:lr=7e-4,batch size=768,使用分层学习率,梯度裁剪,early stop等
3.1.1 Two Tower with Classification.
我们使用额外的分类任务扩展了双塔模型,对于每个doc,我们从搜索日志中收集了一些列相关的query,维护了一个45k的最常见query列表。将此视为一个多标签多类别分类任务
3.2 Training
训练数据 除了传统需要正负样本的监督数据,负样本我们采样了query到其他doc,正样本可从搜索日志中获得,我们通过过滤以下事件序列,从Facebook Marketplace搜索日志创建query-doc数据集:(1)用户搜索查询,(2)点击产品,(3)向市场卖家发送消息,以及(4)卖家回复。如果所有4个事件都发生在短时间内(如24小时),则用户可能找到了他们要查找的内容,因此该query与doc相关。
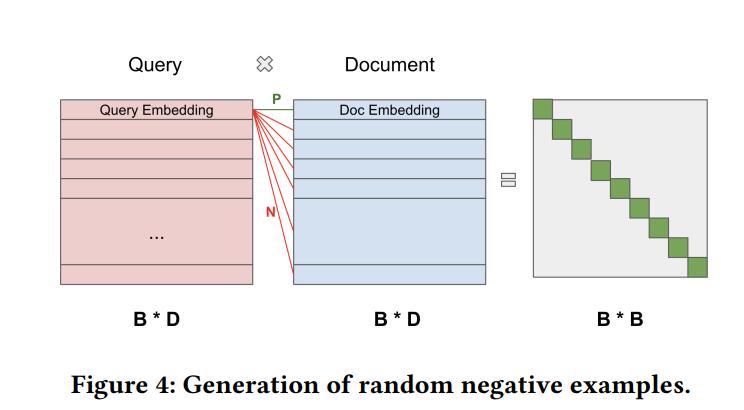
负样本采样在每个batch中,我们计算query-doc互相之间的余弦分数,结果矩阵中行为query,列为doc,doc di与query qi相似,与其他不相似,因此转换为一个多分类任务,类别数为batch size B
3.3 Curriculum Training
除了batch内的负采样,我们还使用了课程学习。第一阶段,我们使用in-batch的负采样方法让模型先收敛,第二阶段,我们希望喂入更难的样本,传统方式是使用分开的难样本数据喂入到模型中,我们仍然使用余弦矩阵(B*B),挑选出每行中最高分数dj作为难的负样本(除了对角线),因此我们获得了(qi,di,dj)的训练数据(三元组对),尝试了BCE和margin rank loss,margin rank loss效果最好(margin 在0.1至0.2之间)。
3.4 Evaluation
Batch recall@K、ROC AUC、KNN Recall@K
3.5 Speeding up model inference
Torch Just-In-Time (JIT)
We experimented with two XLM models in
the query tower: one with 2 layers, 4 attention heads and 128 sentence embedding dimension and the other with 3 encoder layers, 4
attention heads and 256 sentence embedding dimension. We found
the former to have a P99 latency of 1.5ms while the latter had a
P99 latency of 3.5ms while the performance gain was minimal.
4 SYSTEM ARCHITECTURE

CONCLUSION
本文提出了Que2Search,使用多任务与多模态的方式学习query和product的表示。
分享了为搜索用例调优和部署基于BERT的query理解模型的经验,并在99%分为实现了1.5毫秒的推断时间。
同时分享了部署情节,以及关于部署步骤的实用建议,以及如何在搜索语义检索和排名中集成Que2Search组件。