
本章主要介绍几款主流的搜索引擎工具:Lucene、Solr、Elasticsearch,因为在搜索、推荐和广告等场景中会越来越多地使用这些搜索引擎工具。
1.Lucene简介
Lucene是一种高性能、可伸缩的信息搜索引擎,最初由鼎鼎大名的Doug Cutting开发,是基于Java实现的开源项目。Lucene采用了基于倒排表的设计原理,可以非常高效地实现文本查找;在底层采用了分段的存储模式,大大提升了读写性能。Lucene作为搜索引擎,优点是具有成熟的解决方案,低成本,快速上手;支持多种格式索引。缺点是不能友好地支持分布式扩展,可靠性差等。所以在实际应用中,我们需要根据特定场景评估Lucene是否适合于当前场景。
1.1 Lucene的由来及现状
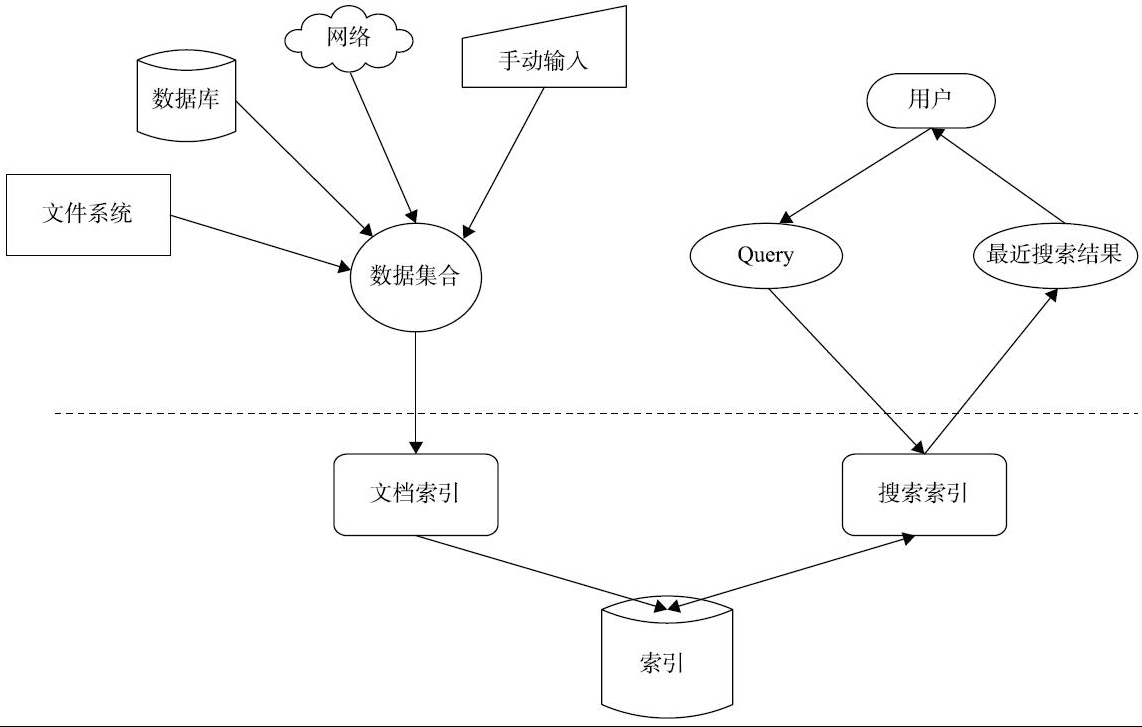
为了更好地理解Lucene,我们先看一下全文索引。Lucene搜索架构如上图所示。
数据包括结构化和非结构化数据。结构化数据是指具有固定格式或有限长度的数据,如数据库、元数据等。非结构化数据是指长度不固定或无固定格式的数据,如邮件、HTML、Word文档等。因此,根据数据分类,我们可以把搜索分为两种:对结构化数据的搜索,如对数据库的搜索,可以使用SQL语句;对非结构化数据的搜索,如使用Windows搜索、grep命令。百度、Google等搜索引擎对非结构化数据搜索采用的方法包括顺序扫描。所谓顺序扫描,即一个文档一个文档查,逐行扫描,直到扫描完成为止。对于一个500GB或者更大的源文件,按照这种方式处理,可能需要花费几个小时甚至数天的时间。简单来说,这种方式只适合于小文档搜索,直接方便。顺序扫描处理非结构化数据很慢,而处理结构化数据速度非常快,我们是否可以考虑把非结构化数据转换成结构化数据?那么具体怎么转换呢?举个例子,根据新华字典检字表的音节和部首,我们可按照拼音排序,根据每一个读音指向字的详细页面,迅速定位。按照这种方式,我们先对搜索词进行分词,然后找每个词对应的文本,接着每个词取一个交集,最后获得查询结果。这种先建立索引,再对索引进行搜索的过程就叫作全文检索。
Lucene中常用的核心术语如下。
1)Term:索引里最小的存储和查询单元,对于英文来说一般指一个单词,对于中文来说一般指一个分词后的词。
2)词典(Term Dictionary):也叫作字典,是Term的集合。查找词典中的数据的方法有很多种,每种都有优缺点,比如哈希表比排序数组的检索速度更快,但是会浪费存储空间。
3)倒排表是Lucene的核心思想。一篇文章通常由多个词组成,倒排表记录的是某个词在哪些文章中出现过。倒排表结构如下图所示。词典和倒排表是实现快速检索的重要基石。词典和倒排表是分两部分存储的。倒排表不但存储了文档编号,还存储了词频等信息。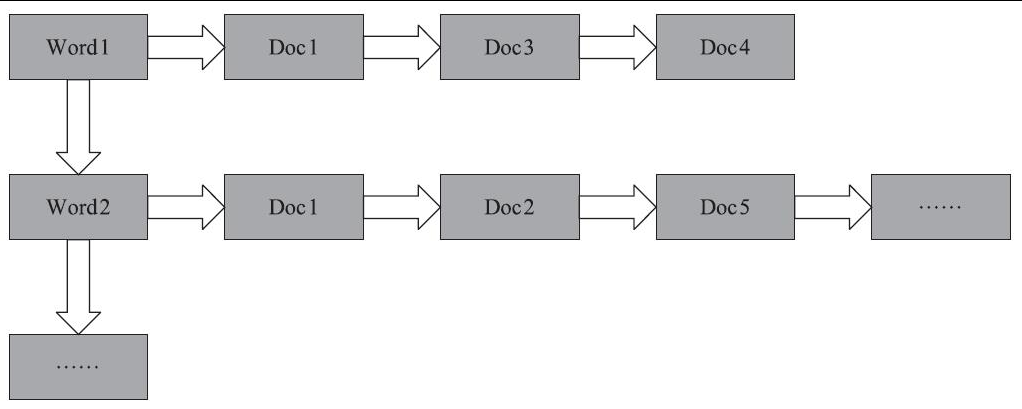
4)正向信息是原始的文档信息,可以用来做排序、聚合、展示等。
5)段是索引中最小的独立存储单元。一个索引文件由一个或者多个段组成。Lucene中的段有不变性,也就是说段一旦生成,只能有读操作,不能有写操作。
Lucene主要模块如下图所示。
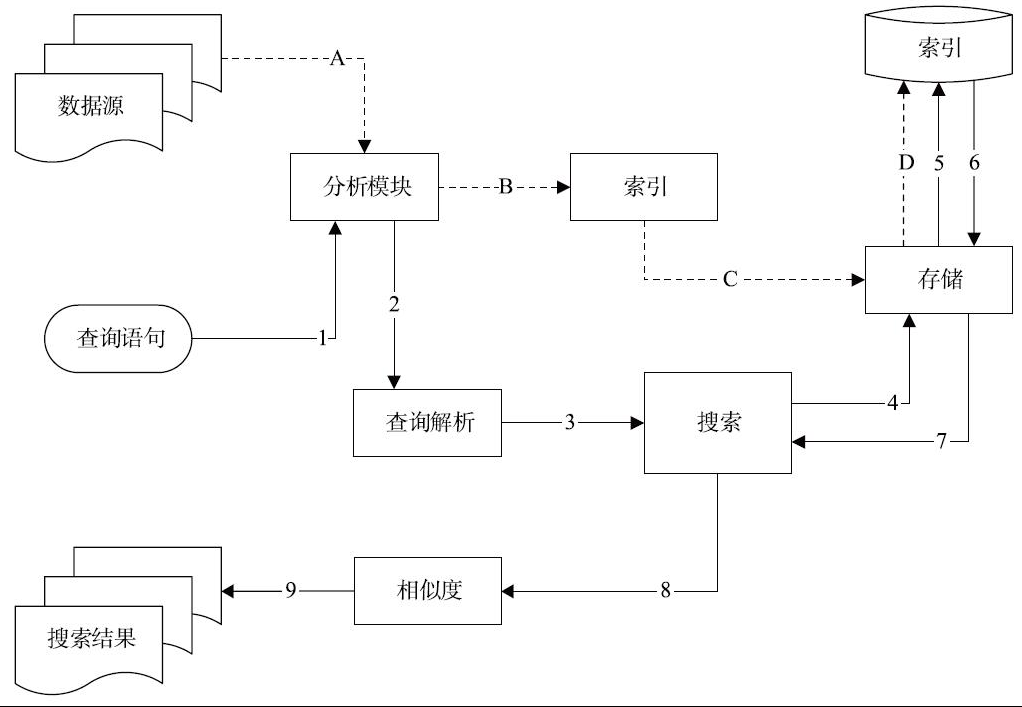
1)分析模块一般由Token和Filter组成。Token是分词器,Filter一般是同义词、大小写转换过滤器等,主要负责词法分析及语言处理,也就是我们常说的分词。通过该模块可获得存储或者搜索的最小单元
2)索引模块主要负责索引的创建工作,包括建立倒排索引、写入磁盘操作。
3)存储模块主要负责索引的读写,主要是针对文件,抽象出和平台文件系统无关的存储信息。
4)查询解析主要负责语法分析,将查询语句转换成Lucene底层可以识别的语句。Lucene的语法分析主要基于JavaCC。JavaCC是词法分析器以及语法分析器的生成器
5)搜索模块主要负责对索引的搜索工作,后续会有一个详细的搜索过程描述。
6)相似度模块主要负责相关性打分和排序。
1.2 Lucene创建索引过程分析
Lucene创建索引过程如下图所示。
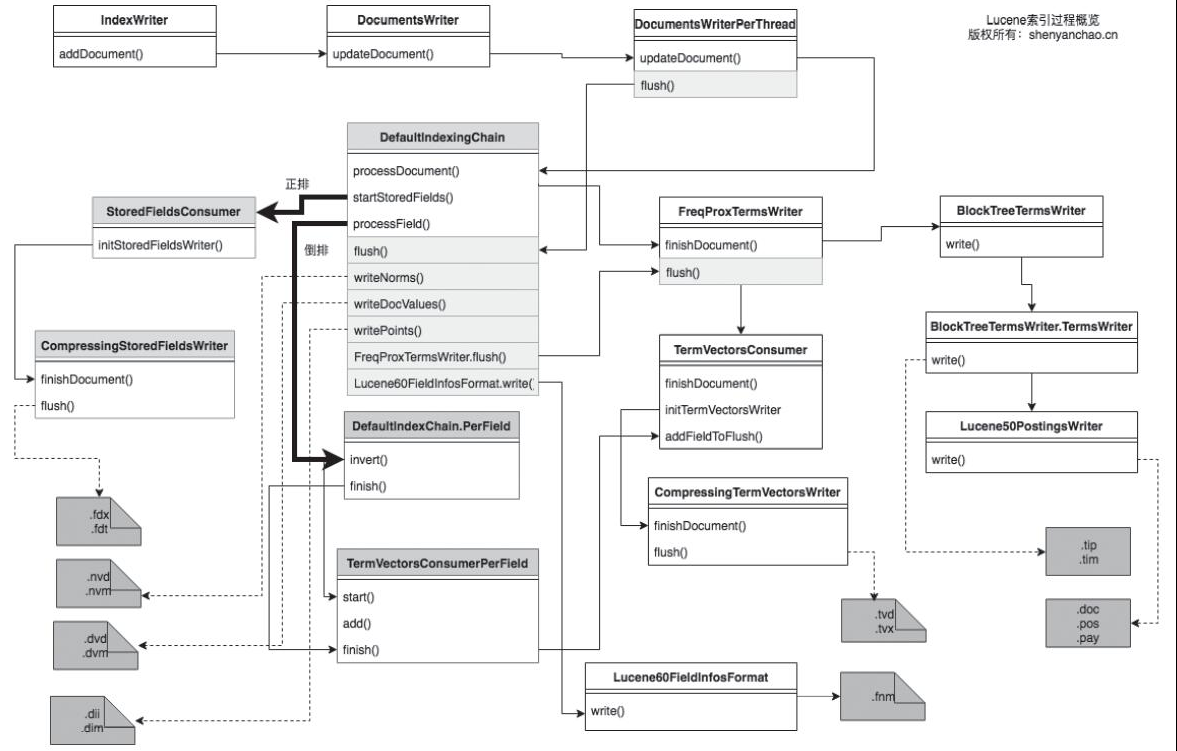
1)添加文档。这个过程会处理没有写入磁盘的数据,遍历需要索引的文件,构造对应的文档和字段,生成DefaultIndexingChain。DefaultIndexingChain是一个默认的索引处理链。后续生成正排表以及倒排表都是在这个链里完成的。
2)构建正排表。在该过程中,我们会使用差值存储、压缩算法将文档写入正排表。
3)构建倒排表,流程如下。
·获取原文档,将原文档传递给分词组件,将文档分成单独的单词,去除标点符号。
·去除停用词。所谓停用词,是语言中最普通的一些词,没有特殊含义,一般情况不能作为搜索的关键词,因此创建索引时候会被去掉,以减少索引量。
·添加同义词
·将得到的词元传给语言处理组件,然后由语言处理组件对得到的词元做一些相关处理,比如大写变小写、单词缩减为词根形式。
·语言处理组件得到的结果被称为词,将词传递给索引组件,并利用得到的词创建一个词典。词典是每个词和词所在的文档ID。
·对词典按字母进行排序,合并相同的词。
·DefaultIndexingChain、processDocument()方法主要用来构建正排信息,而针对每个字段的processField()则通过一系列的操作,构建出倒排信息。
4)写入磁盘。触发写入磁盘文件的是DocumentsWriterPerThread(DWPT)的flush()方法。触发时间可能是以下条件:超过MaxBufferedDocs限制;超过RAMBufferSizeMB限制;人为设置flush()或commit();MergePolicy触发。
经过以上4步处理,Lucene就可以生成一个最小的独立索引单元——段。一个逻辑上的索引(表现为一个目录)由N个段构成。
1.3 Lucene的搜索过程解析
Lucene的搜索过程解析如下。
1)对查询语句进行词法分析、语法分析、语言处理。词法分析主要用来识别单词和关键字,语法分析主要根据查询语句的语法规则形成一棵语法树。
2)搜索索引,得到符合语法树的文档,根据得到的文档和查询语句的相关性,对结果进行排序。
3)计算词的重要性。词的权重表示词对文档的重要程度。越重要的词权重越大,因而权重在计算文档相关性上发挥很大的作用。判断词之间的关系,从而得到文档相关性可用向量空间模型(Vector Space Model,VSM)。
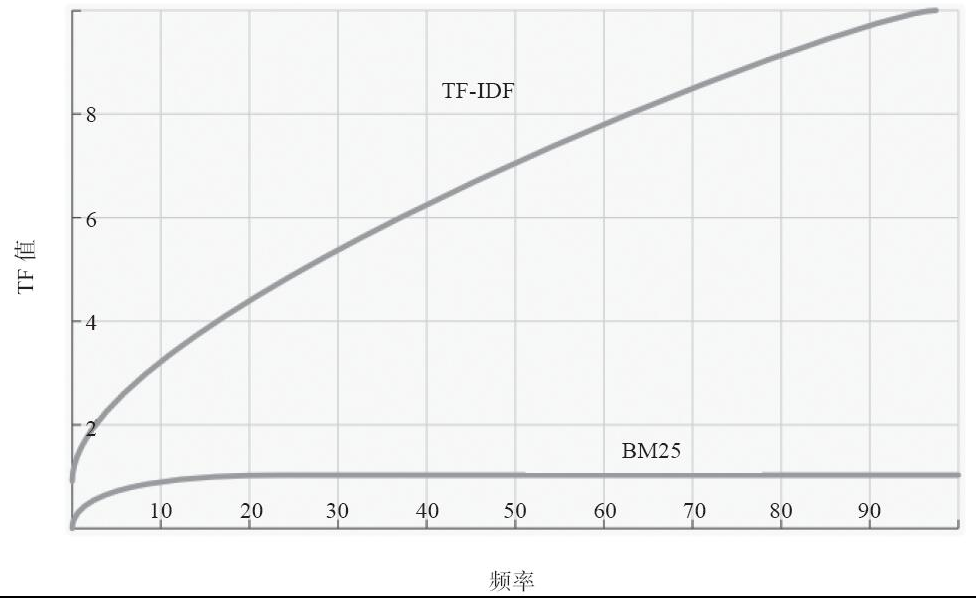
TF-IDF是Lucene默认使用的打分公式,是一种统计方法,用于评估一个字词对一个文件集或一个语料库中其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,同时会随着在语料库中出现的频率成反比下降。Lucene自6.0起使用BM25算法代替了之前的TF-IDF算法。
BM25算法将相关性当作概率问题。相对于TF-IDF,BM25限制TF值的增长极限、平均了文档长度。如图10-5所示,BM25中的TF值有一个上限,文档里出现5~10次的词会比那些只出现一两次的词与搜索相关性更高,但是,文档中出现20次的词几乎与那些出现上千次的词与搜索的相关性几乎相同。
结合代码的详细搜索过程如下。
1)初始化Indexsearch。在该过程中,词典被加载到内存,这步操作是在Directory-Reader.Open()函数中完成的。而完成加载的类叫作BlockTreeTermsReader,每次初始化IndexSearch都会将.tim和.tip加载到内存中,这些操作是很耗时的。
2)Query生成Weight。首先Weight类会将Query重写。重写的目标是将Query组装成一个TermQuery。最典型的,prefixquery会被重写成多个TermQuery。接着计算查询权重,Boost算法通过TF-IDF打分机制,计算出Term的IDF值、QueryNorm值,返回Weight。
1. /** |
3)由Weight生成Scorer。首先根据Term获取TermsEnum,然后根据TermEnum获取DocsEnum,最后生成Scorer。代码如下:
. for (LeafReaderContext ctx : leaves) { |
4)给每个文档打分,并添加到结果集。该过程是最耗时的,需要对每个文档进行打分,并将结果放入生成的容器中。代码如下:
1. static void scoreAll(LeafCollector collector, DocIdSetIterator iterator, |
2 Solr简介
Solr是基于Apache LuceneTM构建的快速、开源的企业搜索平台,是一个Java Web应用,可以运行在任何主流Java Servlet引擎中。Solr服务器的主要构成如下图所示。
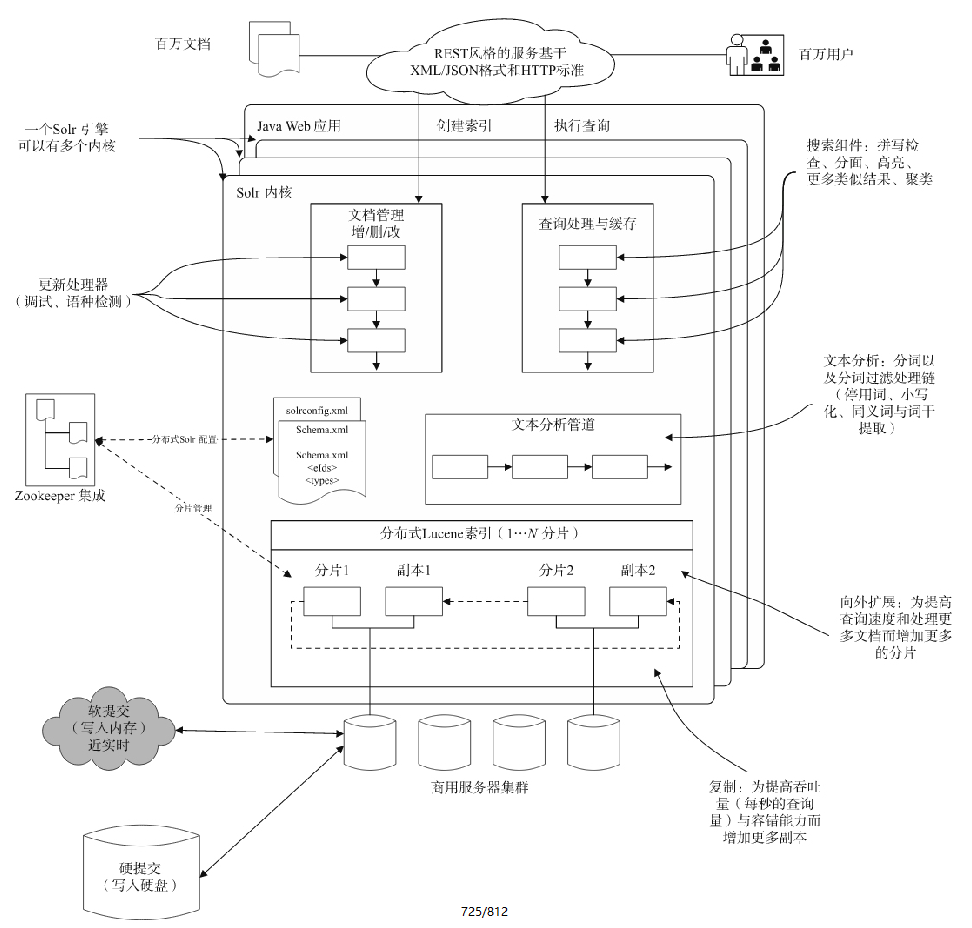
Solr基于已有的XML、JSON格式和HTTP标准,提供简单的类似REST的服务,使得Solr可以被不同编程语言的应用访问。其可以使用Zookeeper实现简易分片和复制,统一配置。为了提高查询速度和处理更多的文档,Solr通过索引分片来实现分布式查询。为了提高吞吐量和容错能力,Solr可以为每个索引分片增加副本,同时把所有的索引复制到其他的服务器,搭建成一个服务器集群,提高吞吐量;也可以通过缓存来提高查询速度,达到近实时查询,并写入硬盘以达到索引持久化。Solr具有高可靠性、可扩展性和容错性,可提供分布式索引、复制和负载均衡查询、自动故障转移和恢复、集中配置等。Solr为很多互联网站点的搜索和导航功能提供支持。
2.1 Solr特性
1)高可靠性。Solr有三个主要的子系统:文档管理、查询处理和文本分析。每一个子系统都是由模块化的管道构成的,通过插件方式实现新功能,这意味着我们可以根据特定的应用需求实现定制。
2)可扩展性。Solr汲取了Lucene速度方面的优点,但因CPU的I/O原则,单台服务器终会达到并发请求的处理上限。为了解决这个问题,Solr提供灵活的缓存管理功能进行扩容,以及通过增加服务器实现增容。
Solr可扩展性体现在两个维度:查询吞吐量和文档索引量。查询吞吐量是指搜索引擎每秒支持的查询数量。文档索引量是指索引文档的大小。为了处理更多文档,我们可以将索引拆分为很小的索引分片,然后在索引分片中进行分布式搜索。
3)容错性。如果索引分片中其中一个索引分片服务器断电,会导致Solr无法继续索引文档和提供查询服务。因此,为了避免此种情况出现,Solr对每一个索引分片添加副本,当其中一个索引分片服务器发生故障时,可以启用副本来索引和处理查询。
2.3 Solr的核心功能
1)复制模式。直到Solr7,SolrCloud能够在集群出现问题的时候提供可靠的故障切换,同时要求副本必须保持同步。
2)自动缩放。自动缩放是Solr一个新功能套件,让SolrCloud集群更加简单和自动化。核心是为用户提供一个规则语法,以便定义如何在集群中分发节点、首选项和策略,以便保持集群平衡。
3)无须手动编写Schema。Schemaless模式是一组Solr功能,它们一起使用时,只需索引数据即可快速地构建Schema。
以下这些Solr功能都是通过solrconfig.xml文件实现的。模式管理:在运行时通过Solr接口进行架构修改,这需要使用支持这些更改的SchemaFactory。更多详细信息,请参阅SolrConfig中的SchemaFactory定义部分。
字段猜测:对于未定义的字段,自动根据FieldValue猜测字段属于哪种类型(Boolean、Integer、Long、Float、Double、Date)。
基于字段猜测自动添加字段到Schema中:未定义的字段会根据FieldValue对应的Java类型自动添加到Schema,请参阅Solr字段类型。
建议关闭Schemaless模式。官网不推荐使用此功能,因为如果字段类型不正确,索引也就不能正常查询(例如存储汉字,我们如果不指定FiledType,就无法正常索引到汉字文档)。
4)结构化非文本字段类型。示例中除了文本外,其他字段都是Solr中常用的字段类型。下面对这些常用的字段类型进行讲解。
Solr中常用字段类型的类图如下图所示。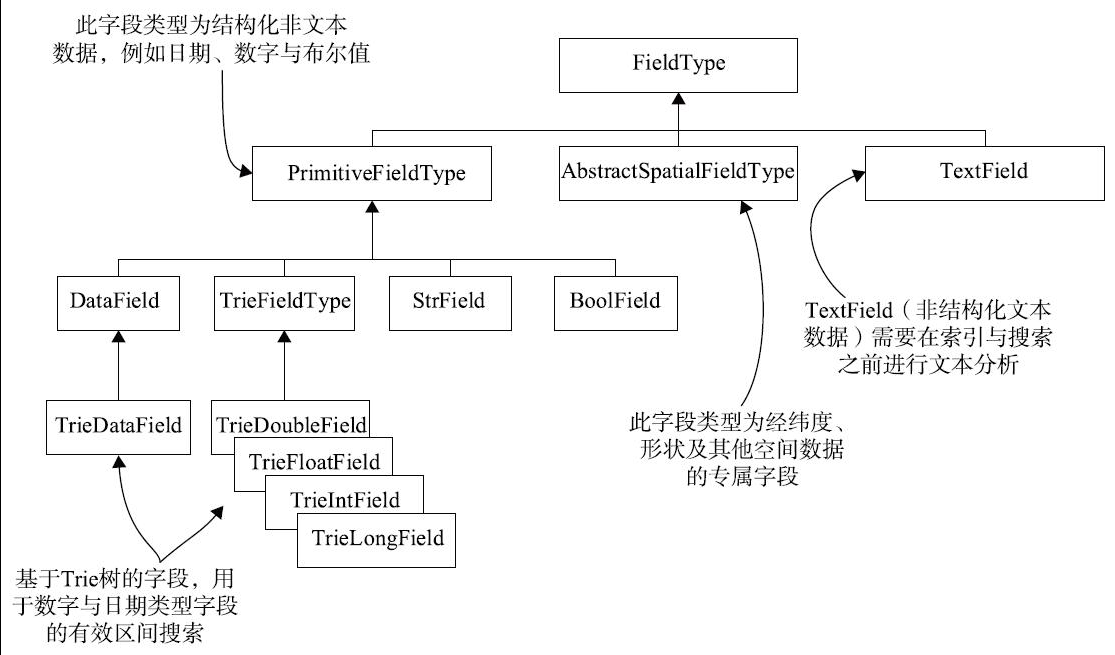
3 Elasticsearch简介
Elasticsearch是一个分布式的开源搜索和分析引擎,适用于对所有类型的数据搜索。Elasticsearch是在Apache Lucene的基础上开发而成,由Elasticsearch N.V.(即现在的Elastic)于2010年首次发布。Elasticsearch以其简单的REST风格接口、分布式特性、速度快和可扩展性而闻名,是Elastic Stack的核心组件。Elastic Stack是适用于数据采集、充实、存储、分析和可视化的一组开源工具。人们通常将Elastic Stack称为ELK Stack(代指Elasticsearch、Logstash和Kibana)。目前,Elastic Stack包括一系列丰富的轻量型数据采集代理,这些代理统称为Beats,可用来向Elasticsearch发送数据。
3.1 Elasticsearch的核心概念
1.集群
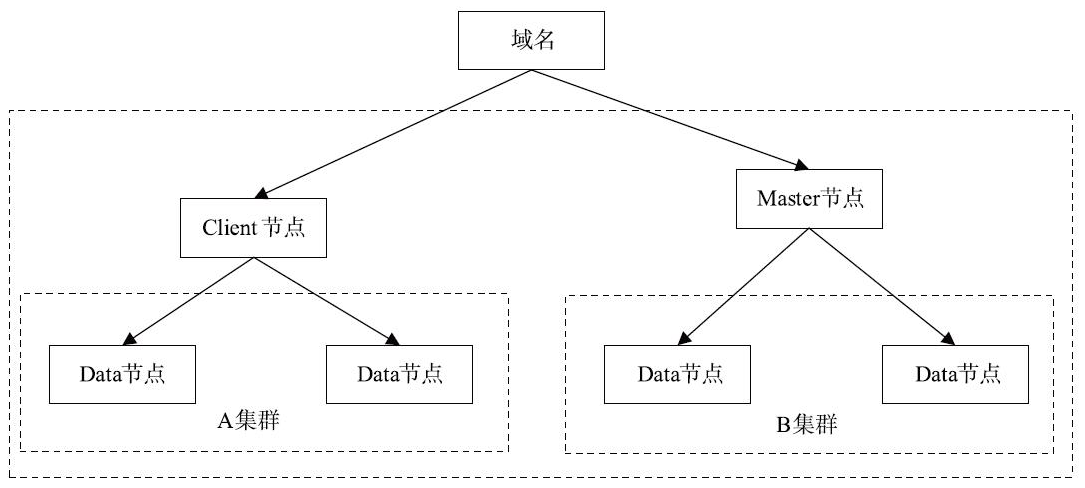
一个集群包含一个或多个节点,用于保存数据。这些节点联合起来提供索引和搜索能力。集群的名称很重要,因为一个节点要加入一个集群,需要配置集群名称。在实际应用中,我们需要确保不同网络环境所使用的集群名称是不同的,否则会导致节点加入其他集群。比如你可以使用logging-dev、logging-stage、logging-prod分别搭建开发、过渡、生产环境。集群只有一个节点,也能正常提供服务。Elasticsearch的集群如下图所示。
2.节点
在集群中,一个节点是一个单独的服务,用来存储数据,为集群的索引和搜索提供支持。集群中的节点也有唯一标识,默认在节点启动的时候会随机指定一个通用唯一标识码(Universally Unique IDentifiter,UUID)。默认情况下,每个节点配置集群名称为Elasticsearch。当在同一个网络环境中,默认启动一些节点,这些节点会组装成一个名为Elasticsearch的集群。如果不使用默认名称,可以为其指定一个名称。节点名称对于集群管理也是很重要的。
3.索引
相对于关系型数据库,索引对应数据库实例。索引中包含许多特征类似的文档。例如,索引可指向用户数据,也可指向产品目录。一个索引需要指定一个名称(必须全部小写)。执行索引、搜索、修改和删除操作时,需要指定对应的索引名称。在一个集群中,我们可以创建多个索引。
4.类型
相对于关系型数据库,类型对应数据库表。一个索引中可以定义多个类型。一个类型可以管理索引中符合特定逻辑的一部分数据。一般来说,类型可定义具有公共字段的文档。例如创建一个博客平台,并且使用一个索引存储所有数据,在这个索引中,可以定义一个类型来存储用户数据,另一个类型来存储博客数据,还可以创建一个类型来存储评论。
5.文档
相对于关系型数据库,文档对应数据库表。文档是能够被索引的基础单元。文档可以存储用户信息,也可以存储产品信息。Elasticsearch中的文档使用JSON格式来存储数据。需要注意,文档必须被索引或分配给索引的类型中。
3.2 Elasticsearch的核心功能
1.近实时
Elasticsearch索引是由段组成的。查询一条数据要经过分钟级别的延迟才能被搜索到,瓶颈点主要在磁盘。持久化一个段需要利用fsync()函数确保其写入物理磁盘,但因为涉及I/O操作,比较耗时,不能每索引一条数据就执行一次,所以引入了轻量级处理方式——FileSytemcache,即先将写入Elasticsearch的文档收集到索引缓冲区并重写成一个段,然后再写入FileSytemcache,之后经过一定间隔时间或者外部触发才写入磁盘,但是写入FileSytemcache后就可以打开和查询,保证短时间查询到数据。所以,Elasticsearch是近实时的。
2.分片或副本
在实际应用中可能存在这样的场景,索引存储超过了节点的物理存储容量。为了解决这些问题,Elasticsearch提供了为索引切分成多个分片的功能。当创建索引的时候,我们能够定义索引被分割成多少个分片。每一个分片支持独立索引,可以分配到集群中任何一个节点。使用分片有两个重要原因:允许水平分割文档,分布式存储;多个节点提供查询,提高了吞吐量。
一个查询发出后去哪些分片请求数据,这些对于用户来说都是透明的。在网络环境中,节点或分片中的数据可能丢失。Elasticsearch提供了故障转移功能,就是副本。Elasticsearch允许为一个分片创建一个或多个副本。分片和副本又称为主/副分片。使用副分片有两个重要原因:主/副分片不会存储在一个节点中,因此副分片可防止主分片数据丢失导致查询不能继续;当进行搜索的时候,允许搜索所有的副分片,提高了搜索性能。
一个索引可以分成多个副分片。每个索引都有主分片(索引切割后的分片,又称原始分片)和副分片(从原始分片复制出来的)。主分片数量和副分片数量在创建索引的时候可以被指定。当索引创建后,我们可以改变副分片数量,但是不能改变主分片数量。因为某个文档分配在哪个分片,是在设置分片数量的时候就已经确定的。如果改变主分片数量,可能导致查询为空。
3.选主算法
Elasticsearch使用的是Master-slave方式,相对于分布式哈希表,可以支持每小时数千节点的加入和离开。但是在相对稳定的网络中,Master模式比较适合。那么在Master-salve模式下,怎么选主算法呢?其实,选择一个合适的主算法对于Elasticsearch是至关重要的。Elasticsearch使用的是Bully算法,功能强大,灵活性高。相对于Paxos算法,Bully算法实现简单,假定所有节点都有唯一ID,对ID排序,任何时候的当前主流程都是参与集群的最高节点ID。Bully算法的特点是易于实现,但是在最大节点ID不稳定的场景下会出现集群假死的情况。Elasticsearch通过推迟选举直到当前的主流程失效的方法来解决假死问题。但是,另一个问题又来了——脑裂。Elasticsearch通过法定得票人数过半来解决脑裂问题。
4.高可用
Elasticsearch使用乐观锁控制并发。因为乐观锁的使用场景是读多写少,而Elasticsearch恰好符合这一场景,如果按照悲观锁的策略,会大大降低吞吐量。Elasticsearch基于版本号进行乐观锁并发控制,以确保新版本不会被旧版本覆盖,由应用层来处理具体的冲突。对于写操作,一致性级别包括quorum/one/all,默认为quorum,即只有当大多数分片可用时才允许写操作。即使大多数分片可用,也可能存在因为网络故障使写入副分片失败的情况,此时分片将会在不同的节点重建。对于读操作,replication可以设置为sync,这样主分片和副分片都搜索完成才返回结果。如果将replication设置为async,可以通过设置请求参数_preference为primary来查询主分片,确保文档是最新版本。
4 搜索引擎工具对比
1.Solr和Lucene
Solr与Lucene并不是竞争对立的关系,而是Solr依存于Lucene,因为Solr底层的核心技术是使用Lucene来实现的。Solr和Lucene的本质区别有以下三点。
1)Lucene本质上是搜索库,不是独立的应用程序,而Solr是应用程序。
2)Lucene专注于搜索底层的建设,而Solr专注于企业应用。
3)Lucene不负责支撑搜索服务所必需的管理,而Solr负责。
所以,Solr是Lucene面向企业级搜索应用的扩展。
2.Solr和Elasticsearch
1)Solr查询语句比Elasticsearch查询语句简单。
2)Solr利用Zookeeper进行分布式管理,而Elasticsearch自身带有分布式协调管理功能。
3)Solr支持更多格式的数据,Elasticsearch仅支持JSON格式。
4)Solr官方提供的功能较多,Elasticsearch注重核心功能。
5)对于一般的搜索,Solr好于Elasticsearch,但在处理实时搜索时效率不如Elasticsearch。
6)Solr专注于文本搜索,Elasticsearch常用于查询、过滤和分组分析统计。